Resolving Multi-Condition Confusion for Finetuning-Free Personalized Image Generation 论文精读
Published:
Background
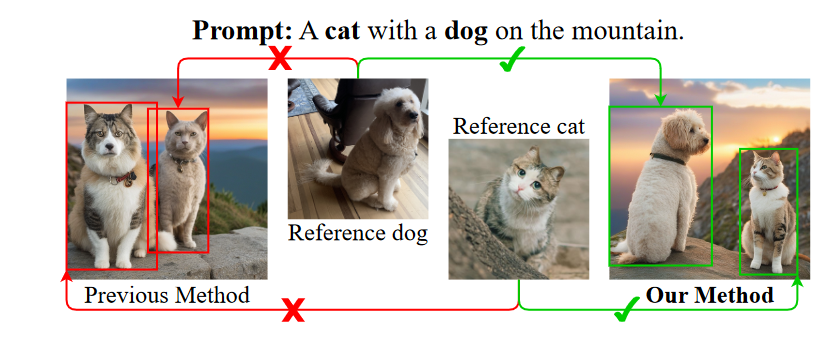
最近的免微调方法,例如IP-Adapter,通过训练额外的交叉注意层,将参考图像特征集成到扩散模型的中间层,更全面地利用参考图像的特征,并实现与微调相当的性能基于方法。当提供多个参考图像时,如果直接应用解耦的交叉注意力,就会遇到对象混淆问题,其中参考图像中的对象特征被分配给生成图像中的错误对象。解耦的交叉注意力在合并多个参考图像时会遇到对象混淆问题,这是本研究旨在解决的问题。
Method
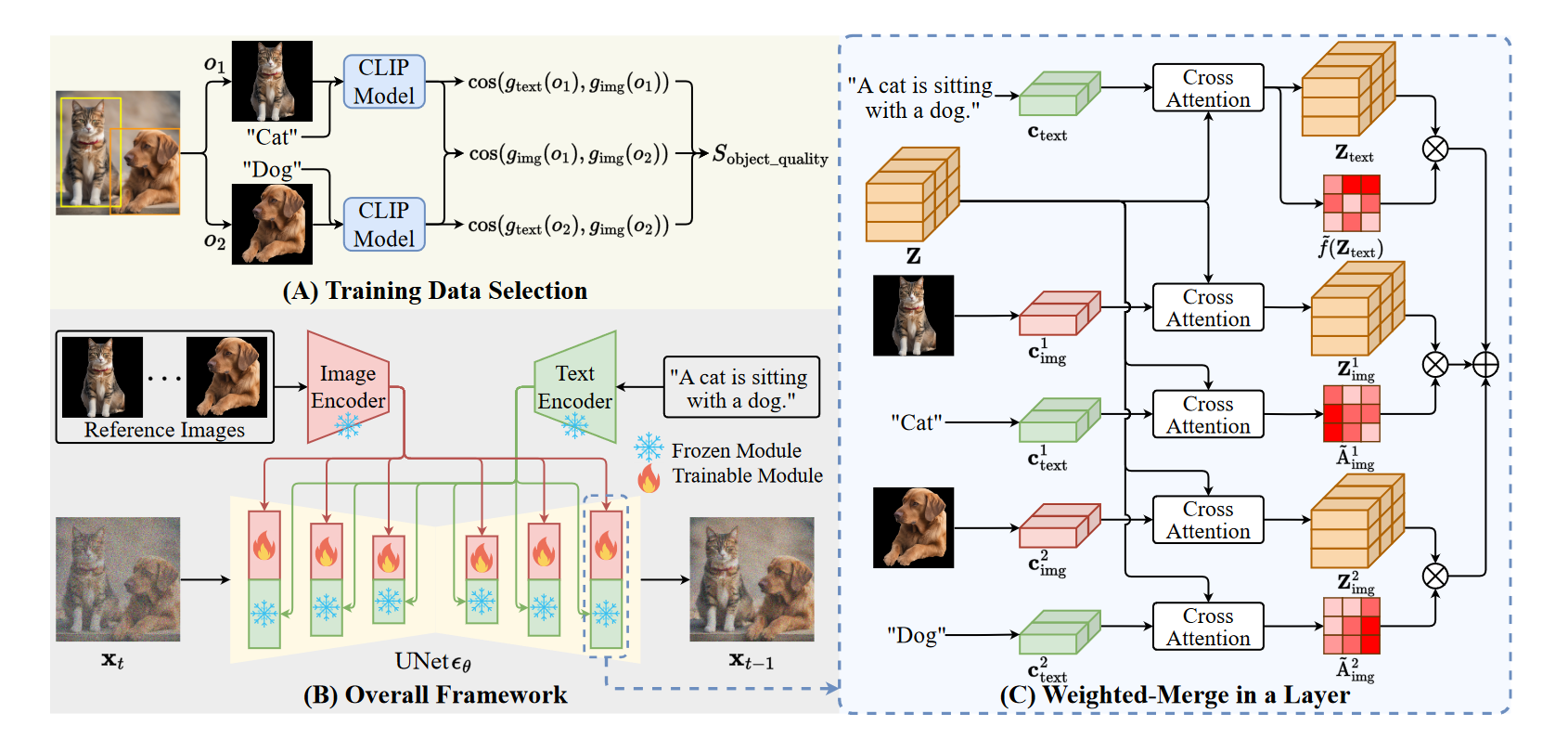
在IP-Adapter中,promt文本的交叉注意力结果如下: \(Z_{\text{text}} = \text{Attn}(Q, K_{\text{text}}, V_{\text{text}}) = \text{Softmax}\left(\frac{QK_{\text{text}}^\top}{\sqrt{d}}\right)V_{\text{text}}\) 参考图片的交叉注意力如下: \(Z_{\text{img}} = \text{Attn}(Q, K_{\text{img}}, V_{\text{img}}) = \text{Softmax}\left(\frac{QK_{\text{img}}^\top}{\sqrt{d}}\right)V_{\text{img}}\) 最终注入到UNet中的结果是: \(Z_{\text{new}} = Z_{\text{text}} + Z_{\text{img}}\)
当参考图片有多个的时候,简单的加权可能无法达到理想的效果,该工作致力于给参考图片的 $Z_{\text{img}}$ 加权,然后加到 $Z_{\text{text}}$ 的对应位置上(这里的位置指的是 $Z_{\text{text}}$ 的第一维,也就是类似于token维)
Object Relevance
该工作计算每个参考图片其文本与原图的相关性:
\[A_{i, \text{img}} = \frac{1}{S_{\text{text}}} \sum_{j=1}^{S_{\text{text}}} \text{Softmax}\left(\frac{K_{i, \text{text}} Q^\top}{\sqrt{d}}\right)[j]\]该式子的含义就是:用参考图片文本描述的每token和UNet中的中间特征 $Z$ 计算相关性,然后取平均。
利用求出的权重进行加权:
\[Z_{\text{new}} = Z_{\text{text}} + \sum_{i=1}^{M} \frac{ A_{i, \text{img}}}{\bar{A}_{i, \text{img}}} \odot Z_{i, \text{img}}\]这里 $ \bar{A}_{i, \text{img}}$ 表示按第维度取平均,即对不同对象进行归一。
### Object Relevance Score
作者设计了一个评价目标相关性的分数。
生成图像 $ x $ 中目标对象的边界框 $ \text{bbox}_x $,使用 Grounding DINO 模型检测。
令 $ x_{\text{noise}} $ 表示对 $ Z_{\text{text}} $ 添加噪声后生成的图像,$ x_{\text{no noise}} $ 表示不添加噪声生成的图像。 计算 $\Delta_{\text{bbox}x}$ 为边界框区域内的像素差异: \(\Delta_{\text{bbox}_x} = \frac{1}{|\text{bbox}_x|} \sum_{p \in \text{bbox}_x} \left| x_{\text{noise}}(p) - x_{\text{no noise}}(p) \right|\) 计算 $\Delta{\text{non bbox}x}$ 为边界框外区域的像素差异: \(\Delta_{\text{non bbox}_x} = \frac{1}{|\text{non bbox}_x|} \sum_{p \in \text{non bbox}_x} \left| x_{\text{noise}}(p) - x_{\text{no noise}}(p) \right|\) 最后,计算对象相关性分数 $ S{\text{object relevance}} $,其公式为: \(S_{\text{object relevance}} = \frac{1}{\| X \|} \sum_{x \in X} \frac{\Delta_{\text{bbox}_x}}{\Delta_{\text{non bbox}_x}}\)
比较了两种添加噪声的策略:均匀合并和加权合并。直接在 $Z_{\text{text}}$ 添加噪声,或者按相关系数添加噪声。结果如下
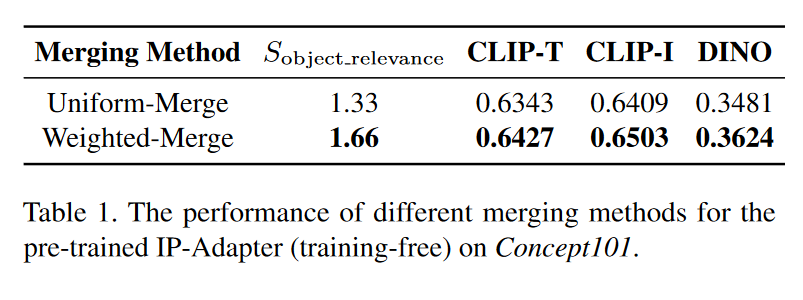
但$Z_{\text{img}}$加到$Z_{\text{text}}$上本来也不是均匀合并,img本身也会和中间特征进行内积,与其考虑怎么给不同图片加权,不如直接给不同图片进行softmax
Training-Based Personalized Image Generation
作者根据(1) 每个单独对象的质量;(2) 每对对象的质量 构建了一个数据集进行训练。第一个因素是确保从原始图像中裁剪出的每个对象与其对应的文本描述一致。第二个因素是选择相似度较低的对象对,这有助于模型解决多个参考图像之间的冲突,并减轻对象混淆问题,而不是错误地将其他相似对象的信息继续添加到当前对象中。评价规则如下: \(S_{\text{object quality}} = S_{\text{single object}} + S_{\text{object pair}}\) \(S_{\text{single object}} = \frac{1}{N_1} \sum_{o \in O_x} \cos(g_{\text{text}}(o), g_{\text{img}}(o))\) \(S_{\text{object pair}} = - \frac{1}{N_2} \sum_{o', o'' \in O_x; o' \neq o''} \cos(g_{\text{img}}(o'), g_{\text{img}}(o''))\) \(N_1 = \| O_x \|, N_2 = \| O_x \| (\| O_x \| - 1)\)
作者从SA-1B中选取Sobject quality分数最高的100k张图进行训练。
文中提到在模型的训练中,存在文本 和图像特征 之间的冲突。为了处理这种冲突,作者提出了一种“加权融合”方法,预测出每个位置是否与对象无关的文本关联。由于难以直接提取这些对象无关文本的特征并计算类似于𝐴的交叉注意力矩阵,作者设计了一种可训练的预测层,用于为这些文本特征预测权重。 \(Z_{\text{new}} = \frac{f(Z_{\text{text}})}{ {\bar f(Z_{\text{text}})}} \odot Z_{\text{text}} + \sum_{i=1}^{M} \frac{A_i^{\text{img}}}}} \odot Z_i^{\text{img}}\)
实际代码是 \(Z_{\text{new}} = Z_{\text{text}} + \frac{f(Z_{\text{text}})}{ {\bar f(Z_{\text{text}})}} \odot \sum_{i=1}^{M} \frac{A_i^{\text{img}}}}} \odot Z_i^{\text{img}}\) f 对位置平均。
Overview
整体的框架图如图
Question
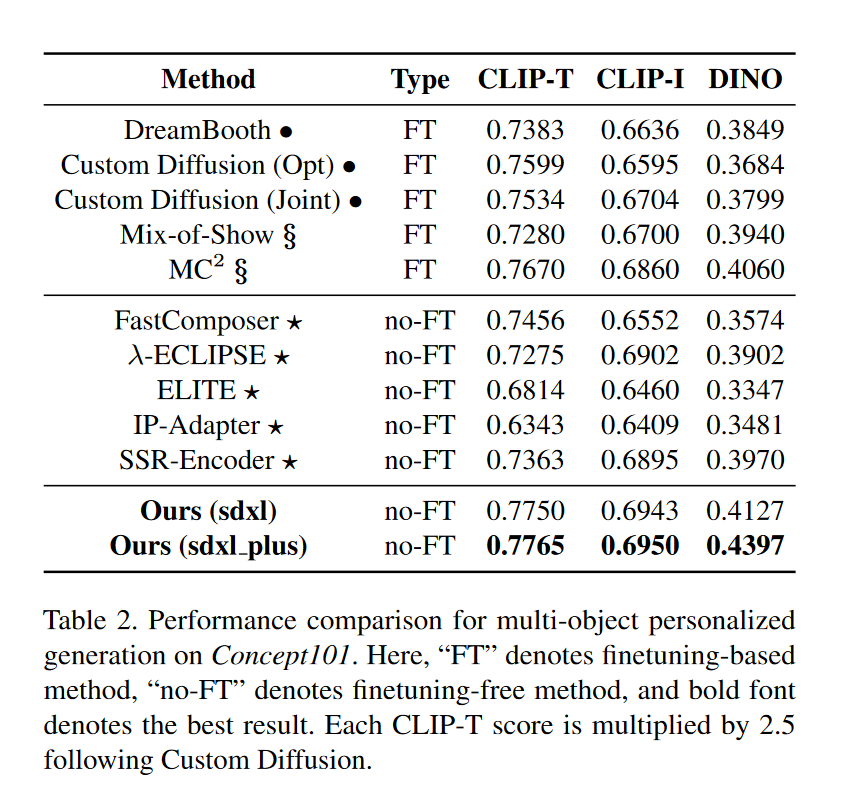
在该工作的实验部分,作者提到他们的工作与IP-Adapter在将多张参考图像情况下的性能比较:
而在消融实验部分,又提到了与多图片均匀添加情况的对比:
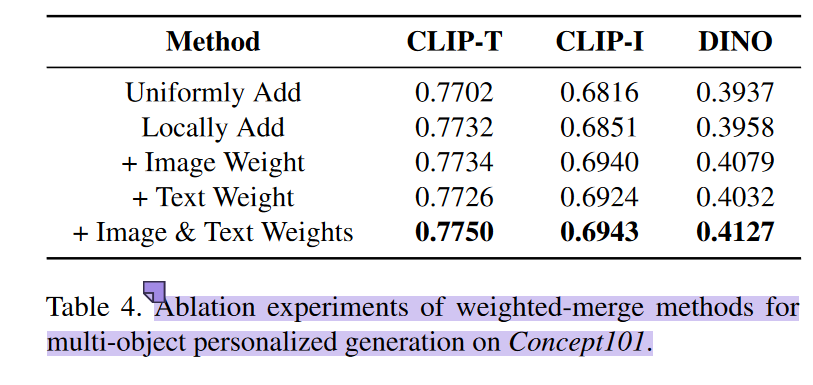
该工作是在IP-Adapter sdxl 模型基础上进行的调整,理论上消融实验中均匀添加的情况就是IP-Adapter处理多张参考图像的默认方式,也就是说消融实验中均匀添加的性能应该与对比实验中IP-Adapter的性能相当,但是文章中给出来的性能差异相当之大,甚至可以掩盖加权求和对于IP-Adapter的性能提升。
我猜测作者在进行消融实验中测试均匀添加情况时,并未使用IP-Adapter的原始参数,而是使用在他们构建的数据集上已经训练好的参数,因此无法排除真正起作用的是在该数据集上的训练。