IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models 论文精读
Published:
Background
仅用文本作为提示的T2I生成模型无法表达图片需要的所有内容,因此希望将图片作为输入进行图片生成。DALL-E 2实现了将图片作为输入,而流行的SD能否也将图片作为输入。
先前的方法是直接在图像嵌入上微调文本条件扩散模型以实现图像提示功能,但微调消除了原来使用文本生成图像的能力,并且这种微调通常需要大量的计算资源,且不可复用。因此希望设计一个轻量级的适配器,即保存SD的性能,又能将图片也作为输入。
Overview
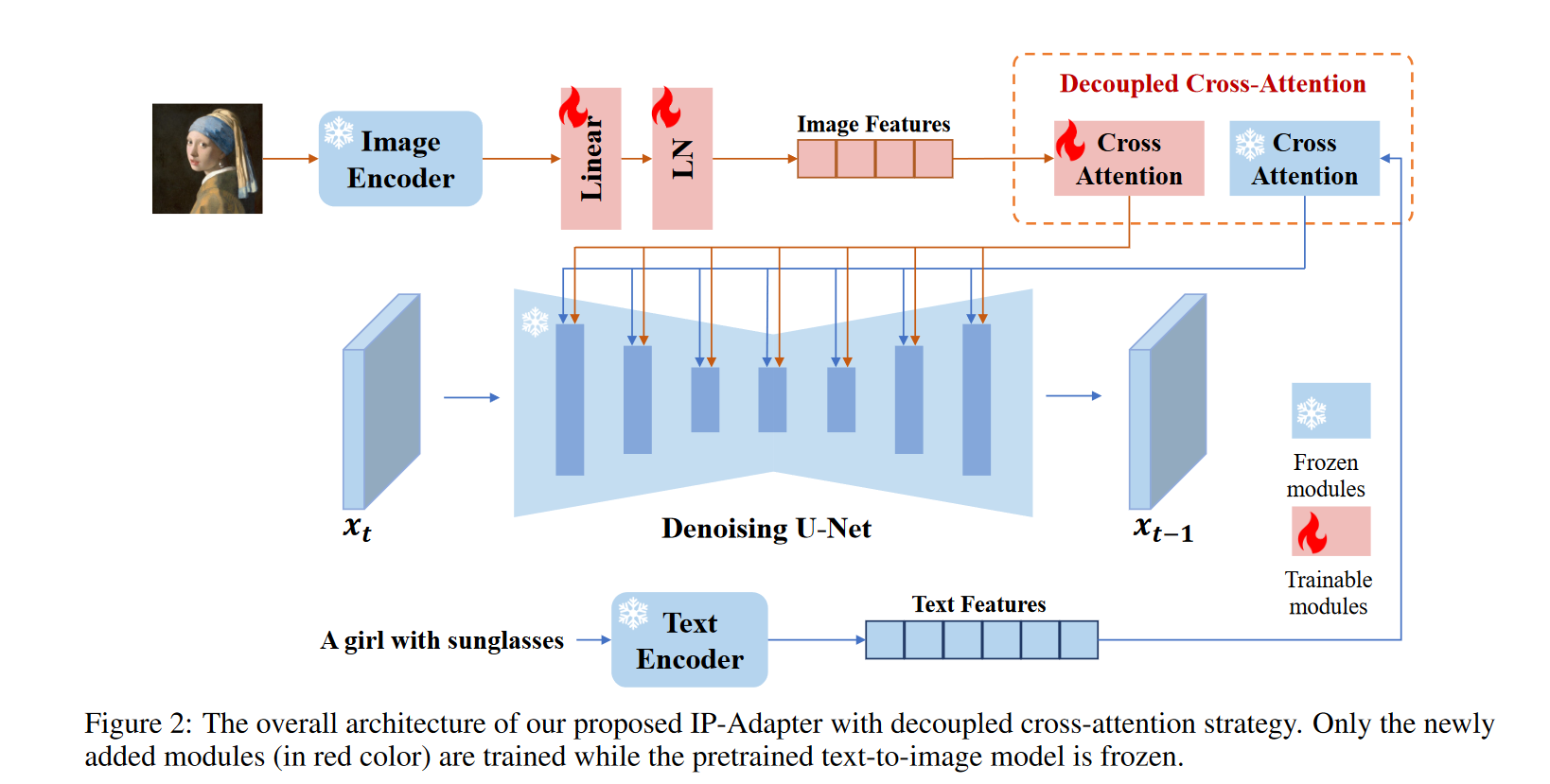
IP-Adapter的结构如上图所示,图片经过CLIP的图片编码器,再过可训练的线性层和归一层将图像嵌入投影为长度为 N 的特征序列,最终进入交叉注意力机制中。
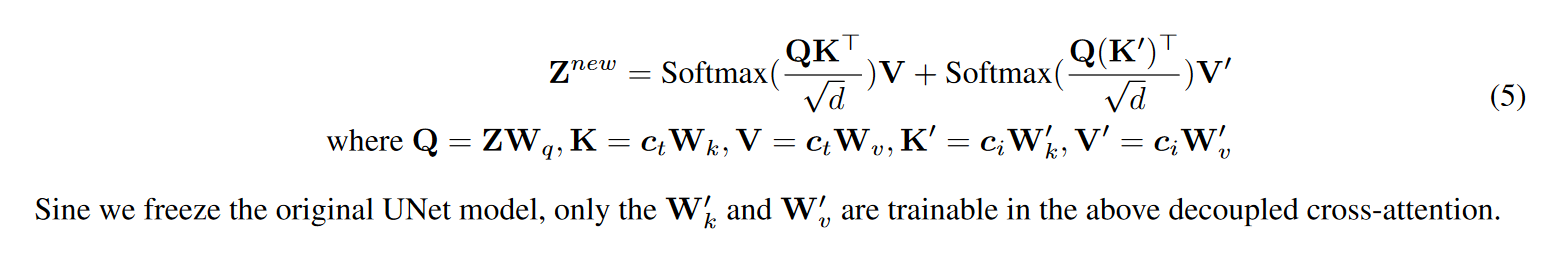
在交叉注意力机制中,图片和文本的编码进入两个不同的Attention,他们共用一个Q矩阵,文本的$W_K,W_V$ 保存不变,训练图片的$W_K,W_V$。 两个Attention如上图进行加和。
Training and Inference
在训练过程中,我们仅优化 IP-Adapter,同时保持预训练的扩散模型的参数固定。IP-Adapter 也在具有图文对的数据集上进行训练,使用与原始 Stable Diffusion 相同的训练目标: \(L_{\text{simple}} = \mathbb{E}_{x_0, \epsilon, c_t, c_i, t} \left[ \| \epsilon - \epsilon_{\theta}( x_t, c_t, c_i, t ) \|^2 \right]\)
推理过程的无分类器引导:
\[\hat{\epsilon}_{\theta}(x_t, c_t, c_i, t) = w \cdot \epsilon_{\theta}(x_t, c_t, c_i, t) + (1 - w) \cdot \epsilon_{\theta}(x_t, t)\]图片条件的注意力权重: \(Z_{\text{new}} = \text{Attention}(Q, K, V) + \lambda \cdot \text{Attention}(Q, K', V')\)
Generalization
类似于 T2I-Adapter,IP-Adapter可以很好直接使用到从SD微调的模型。
Fine-grained Features
针对细粒度特征,设计一个额外的IP-Adapter:首先从 CLIP 编码器的倒数第二层提取网格特征,然后使用一个轻量级的 Transformer 查询网络,定义 16 个可学习的令牌,从这些特征中提取信息,并将其作为交叉注意力层的输入。这样,尽管新的 IP-Adapter 能生成与图像提示更一致的图像,但可能会学习到空间结构,降低生成的多样性。
IP-Adapter和multi-head的思想相似