Adding Conditional Control to Text-to-Image Diffusion Models 论文精读
Published:
Challenge
以端到端的方式学习大型文本到图像扩散模型的条件控制具有挑战性,特定条件的训练数据量可能明显小于一般文本到图像训练可用的数据。使用有限数据直接微调或持续训练大型预训练模型可能会导致过度拟合和灾难性遗忘。本文介绍了 ControlNet,这是一种端到端神经网络架构,可学习大型预训练文本到图像扩散模型(Stable Diffusion)的条件控制。该架构将大型预训练模型视为学习各种条件控制的强大支柱。
Method
我们锁定(冻结)原始块的参数 θ,同时将该块克隆到具有参数 θc 的可训练副本,可训练副本采用外部条件向量 c 作为输入。这种设计保持了模型的原始输出,同时引入新的输入条件向量 c 。可训练的副本通过零卷积层连接到被锁定的模型。
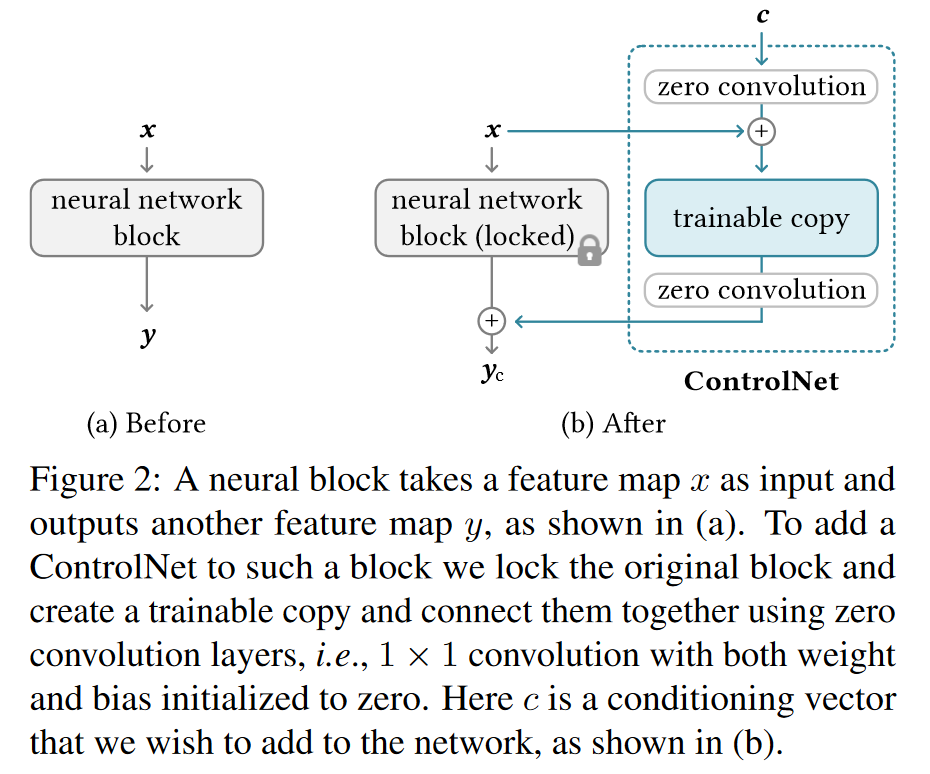
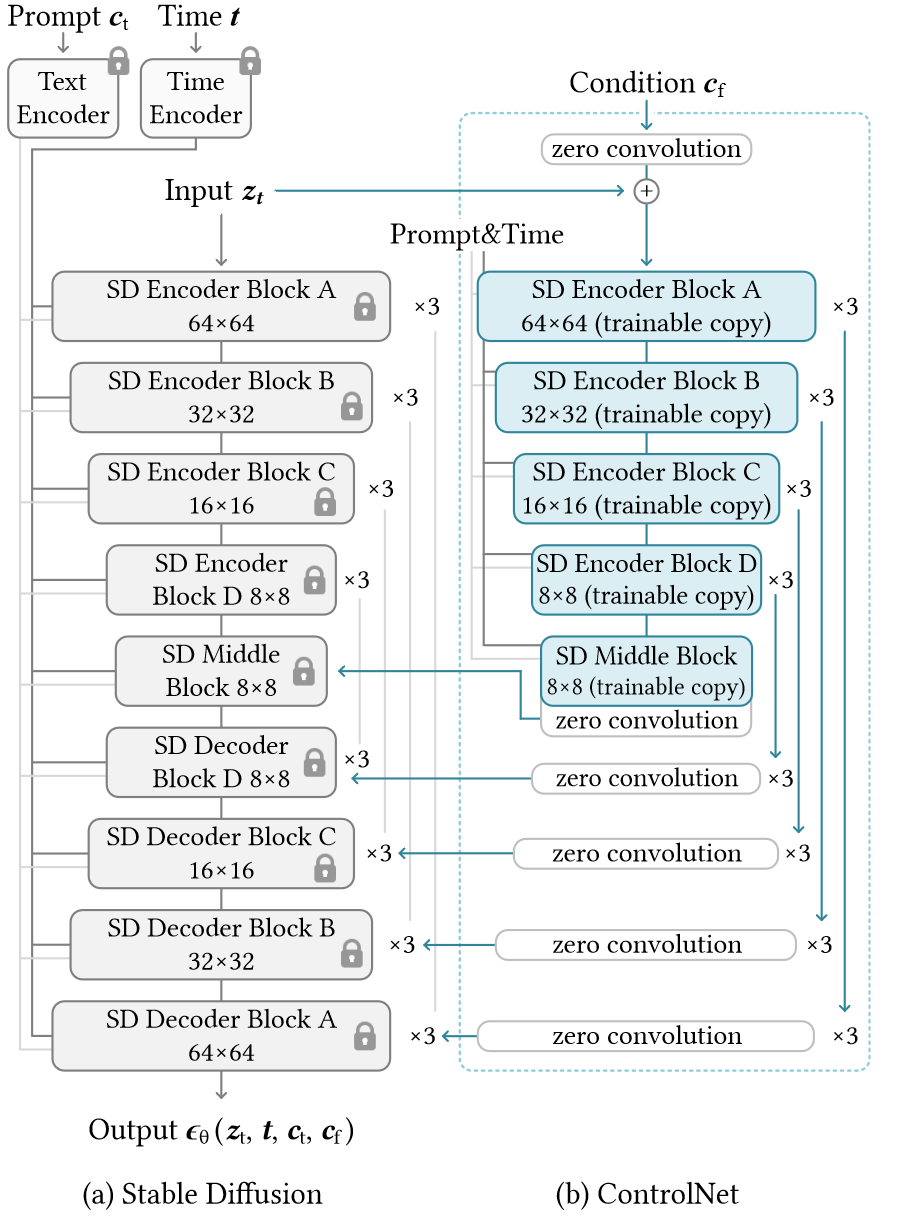
以 Stable Diffusion 的 UNet 为例,使用 ControlNet 创建 12 个编码块和 1 个稳定扩散中间块的可训练副本,输出被添加到 U 网的 12 个跳跃连接和 1 个中间块。在NVIDIA A100 PCIE 40GB, 每次训练迭代中只需要多大约 23% 的 GPU 内存和 34% 的时间。
Training
在一组条件下,包括时间步长 $t$、文本提示 $c_t$,以及任务特定的条件 $c_f$,图像扩散算法学习一个网络 $ε_θ$ 来预测添加到噪声图像 $z_t$ 上的噪声 $ε$。
\[L = E_{z_0, t, c_t, c_f, \varepsilon \sim N(0, 1)} \left[ \|\varepsilon - \varepsilon_{\theta}(z_t, t, c_t, c_f)\|^2_2 \right]\]在训练过程中,我们随机将50%的文本提示 $c_t$ 替换为空字符串。
Inference
使用 CFG 引导加权。CFG 公式:
\[\varepsilon_{prd} = \varepsilon_{uc} + \beta_{cfg} (\varepsilon_c - \varepsilon_{uc})\]其中,$\varepsilon_{prd}$、$\varepsilon_{uc}$、$\varepsilon_c $ 和 $\beta_{cfg}$ 分别表示模型的最终输出、无条件输出、有条件输出和用户指定的权重.
将条件图片加入到条件输出 $\varepsilon_c $ 中, 然后根据每个块的分辨率 $w_i = 64/h_i$,为Stable Diffusion 和 ControlNet 之间的每个连接乘以一个权重wi,以此来平衡CFG影响过低或过高。
对于多个条件图片的输入(例如边缘和姿势),我们可以直接将相应 ControlNet 的输出添加到稳定扩散模型中,不需要额外的加权或线性插值。