LoRA学习笔记
Published:
LoRA+
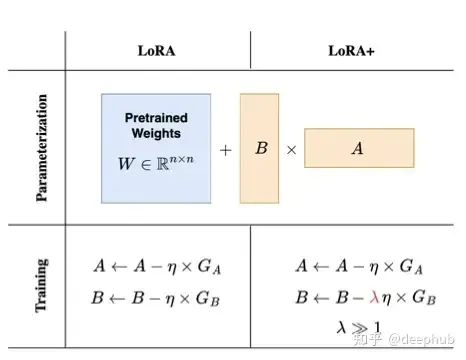 矩阵 B 的初始化为 0,所以需要比随机初始化的矩阵 A 需要更大的更新步骤。通过将矩阵 B 的学习率设置为矩阵 A 的 16 倍,作者已经能够在模型精度上获得小幅提高(约 2%),同时将 RoBERTa 或 Llama-7B 等模型的训练时间加快 2 倍。
矩阵 B 的初始化为 0,所以需要比随机初始化的矩阵 A 需要更大的更新步骤。通过将矩阵 B 的学习率设置为矩阵 A 的 16 倍,作者已经能够在模型精度上获得小幅提高(约 2%),同时将 RoBERTa 或 Llama-7B 等模型的训练时间加快 2 倍。
VeRA
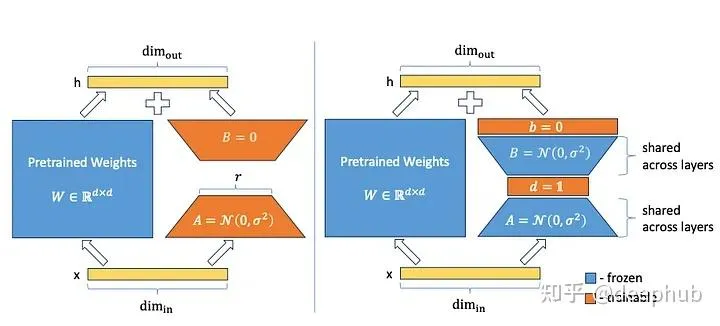 VeRA 的作者通过引入向量 d 和 b 只训练这些相关的子网络,与原始的 LoRA 方法相反,矩阵 A 和 b 是冻结的,并且矩阵 B 不再被设置为零,而是像矩阵 A 一样随机初始化。
VeRA 的作者通过引入向量 d 和 b 只训练这些相关的子网络,与原始的 LoRA 方法相反,矩阵 A 和 b 是冻结的,并且矩阵 B 不再被设置为零,而是像矩阵 A 一样随机初始化。
LoRA-FA
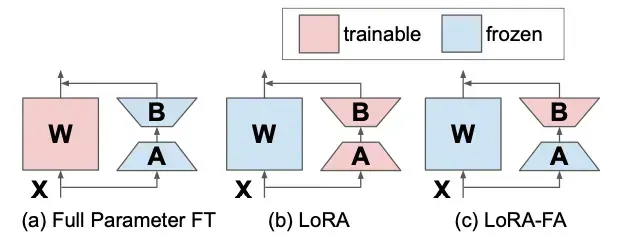 矩阵 A 在初始化后被冻结,因此作为随机投影。矩阵 B 不是添加新的向量,而是在用零初始化之后进行训练(就像在原始 LoRA 中一样)。
矩阵 A 在初始化后被冻结,因此作为随机投影。矩阵 B 不是添加新的向量,而是在用零初始化之后进行训练(就像在原始 LoRA 中一样)。
LoRa-drop
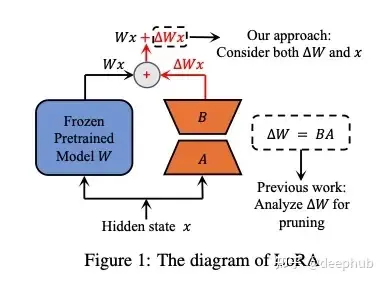 LoRA 矩阵可以添加到神经网络的任何一层。LoRA-drop[5] 则引入了一种算法来决定哪些层由 LoRA 微调,哪些层不需要。
LoRA 矩阵可以添加到神经网络的任何一层。LoRA-drop[5] 则引入了一种算法来决定哪些层由 LoRA 微调,哪些层不需要。
LoRA-drop 包括两个步骤。在第一步中对数据的一个子集进行采样,训练 LoRA 进行几次迭代。然后将每个 LoRA 适配器的重要性计算为 BAx,其中 A 和 B 是 LoRA 矩阵,x 是输入。这是添加到冻结层输出中的 LoRA 的输出。如果这个输出很大,说明它会更剧烈地改变行为。如果它很小,这表明 LoRA 对冻结层的影响很小,可以忽略。
选择最重要的 LoRA 层也有不同的方法:可以汇总重要性值,直到达到一个阈值(这是由一个超参数控制的),或者只取最重要的 n 个固定 n 的 LoRA 层。无论使用哪种方法,还都需要在整个数据集上进行完整的训练(因为前面的步骤中使用了一个数据子集),其他层固定为一组共享参数,在训练期间不会再更改。
AdaLoRA
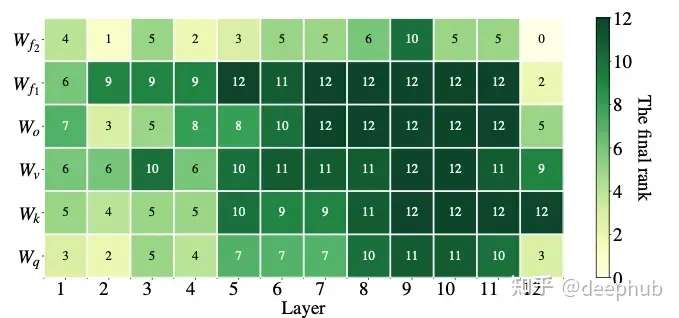 有很多种方法可以决定哪些 LoRA 参数比其他参数更重要,AdaLoRA[6] 就是其中一种。AdaLoRA 的作者建议考虑将 LoRA 矩阵的奇异值作为其重要性的指标。
有很多种方法可以决定哪些 LoRA 参数比其他参数更重要,AdaLoRA[6] 就是其中一种。AdaLoRA 的作者建议考虑将 LoRA 矩阵的奇异值作为其重要性的指标。
与上面的 LoRA-drop 有一个重要的区别是,在 LoRA-drop 中层的适配器要么被完全训练,要么根本不被训练。而 AdaLoRA 可以决定不同的适配器具有不同的秩(在原始的 LoRA 方法中,所有适配器具有相同的秩)。
DoRA
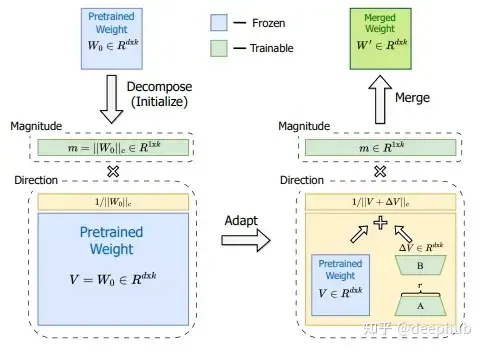 把矩阵分解成方向矩阵和长度矩阵,再微调。
把矩阵分解成方向矩阵和长度矩阵,再微调。
Delta-LoRA
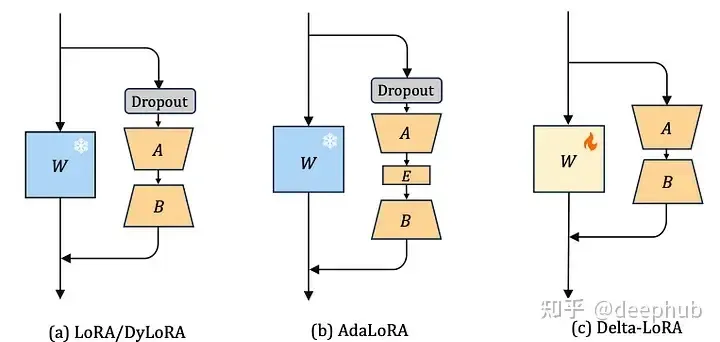 Delta-LoRA 的作者提出用 AB 的梯度来更新矩阵 W,AB 的梯度是 A*B 在连续两个时间步长的差。这个梯度用超参数 ( \lambda ) 进行缩放,( \lambda ) 控制新训练对预训练权重的影响有多大。
Delta-LoRA 的作者提出用 AB 的梯度来更新矩阵 W,AB 的梯度是 A*B 在连续两个时间步长的差。这个梯度用超参数 ( \lambda ) 进行缩放,( \lambda ) 控制新训练对预训练权重的影响有多大。 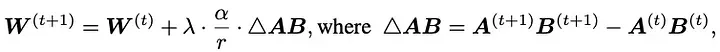
MoRAL
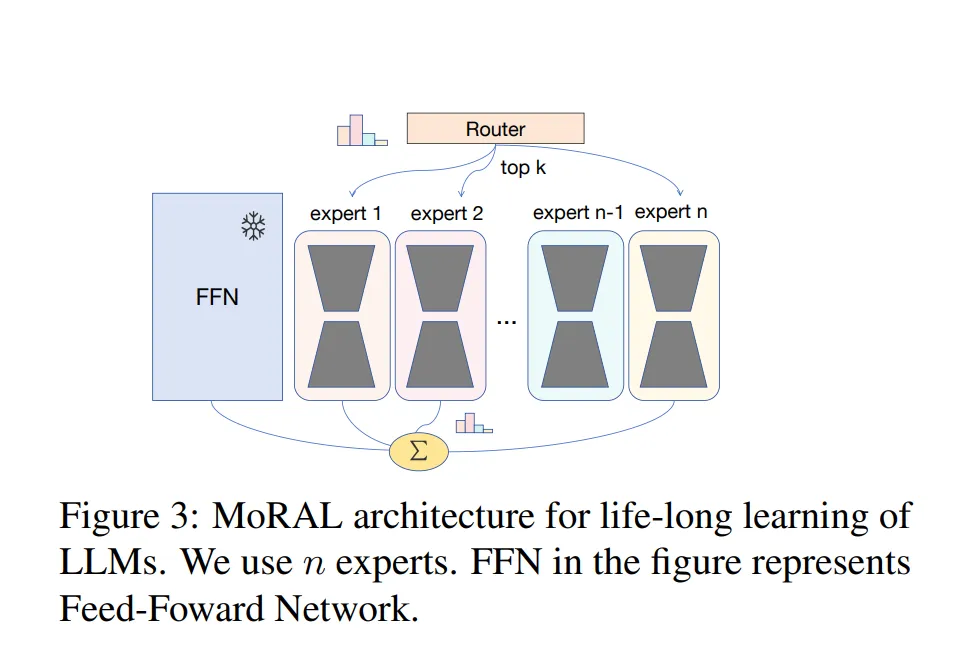 引入低秩矩阵来分解与预训练 LLMs 对应的权重矩阵。使用这些低秩矩阵作为专家,应用在预训练模型之上。通过一个门控机制,也被称为路由网络,允许在多个专家上进行条件计算。
引入低秩矩阵来分解与预训练 LLMs 对应的权重矩阵。使用这些低秩矩阵作为专家,应用在预训练模型之上。通过一个门控机制,也被称为路由网络,允许在多个专家上进行条件计算。
QLoRA
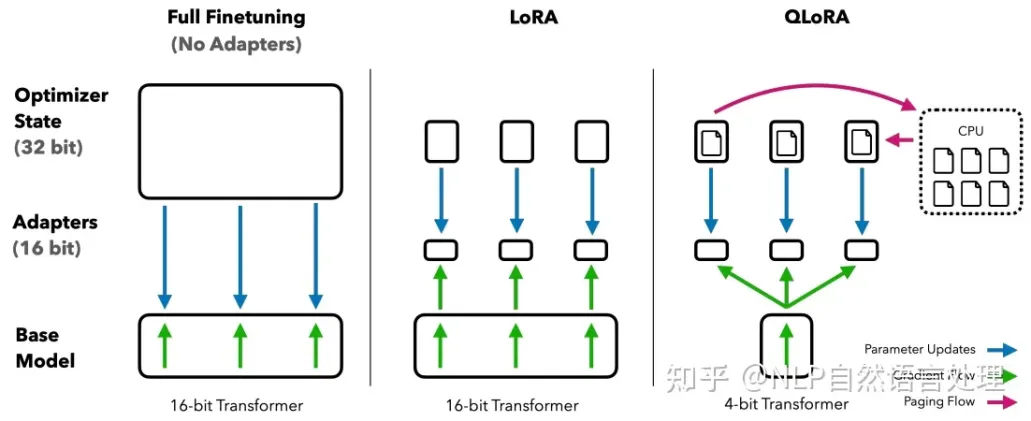 QLORA 是一种针对深度神经网络的低精度量化和微调技术,能够实现高保真的 4 位微调。它采用了两种技术——4 位 NormalFloat (NF4) 量化和 Double Quantization。同时,引入了 Paged Optimizers,它可以避免梯度检查点操作时内存爆满导致的内存错误。
QLORA 是一种针对深度神经网络的低精度量化和微调技术,能够实现高保真的 4 位微调。它采用了两种技术——4 位 NormalFloat (NF4) 量化和 Double Quantization。同时,引入了 Paged Optimizers,它可以避免梯度检查点操作时内存爆满导致的内存错误。
QLORA 包含一种低精度存储数据类型(通常为 4-bit)和一种计算数据类型(通常为 BFloat16)。在实践中,QLORA 权重张量使用时,需要将张量去量化为 BFloat16,然后在 16 位计算精度下进行矩阵乘法运算。
- 4bit NormalFloat(NF4):对于正态分布权重而言,一种信息理论上最优的新数据类型,该数据类型对正态分布数据产生比 4-bit 整数和 4-bit 浮点数更好的实证结果。
- 双量化:对第一次量化后的那些常量再进行一次量化,减少存储空间。
- 分页优化器:使用 NVIDIA 统一内存特性,该特性可以在 GPU 偶尔 OOM 的情况下,进行 CPU 和 GPU 之间自动分页传输,以实现无错误的 GPU 处理。该功能类似于 CPU 内存和磁盘之间的常规内存分页。使用此功能为优化器状态(Optimizer)分配分页内存,在 GPU 内存不足时将其自动卸载到 CPU 内存,并在优化器更新步骤需要时将其加载回 GPU 内存。
S-LoRA
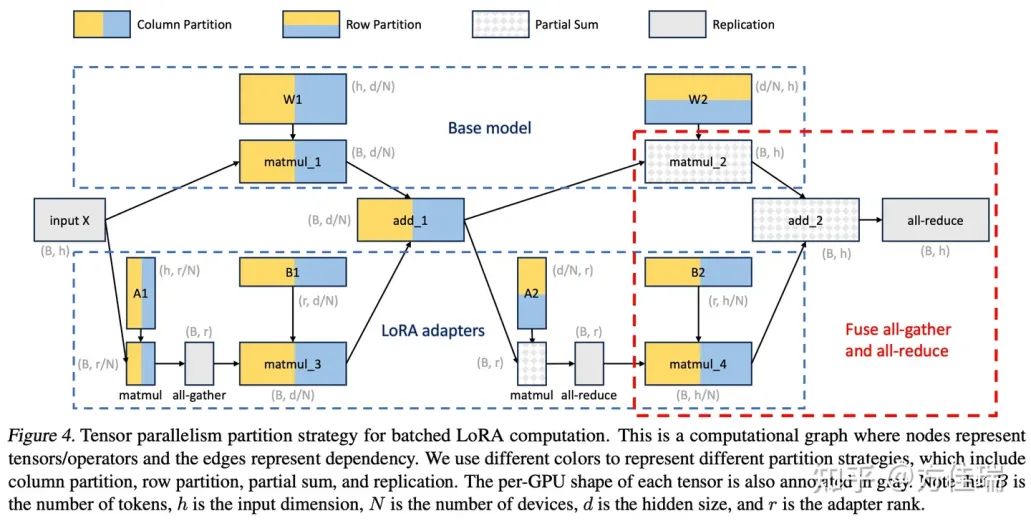 如果将多 adapter 单 base model 部署在多卡环境中,需要 Tensor Parallelism 帮助。这种并行方式较为简单,如下图所示,展示了一个两层 MLP 的切分方法,比较特殊的是将 matmul_4 的 all-gather 操作与最终的 all-reduce 操作融合在一起。作者声称这是本文一大创新之处。
如果将多 adapter 单 base model 部署在多卡环境中,需要 Tensor Parallelism 帮助。这种并行方式较为简单,如下图所示,展示了一个两层 MLP 的切分方法,比较特殊的是将 matmul_4 的 all-gather 操作与最终的 all-reduce 操作融合在一起。作者声称这是本文一大创新之处。
将层 MLP 的切分策略可以拓展到 self-attention 层。与 Megatron-LM 策略类似,作者对 self-attention 的 head 维度进行分区。Q-K-V 的权重矩阵可以看作是 W1,output 矩阵的权重矩阵可以看作是 W2。 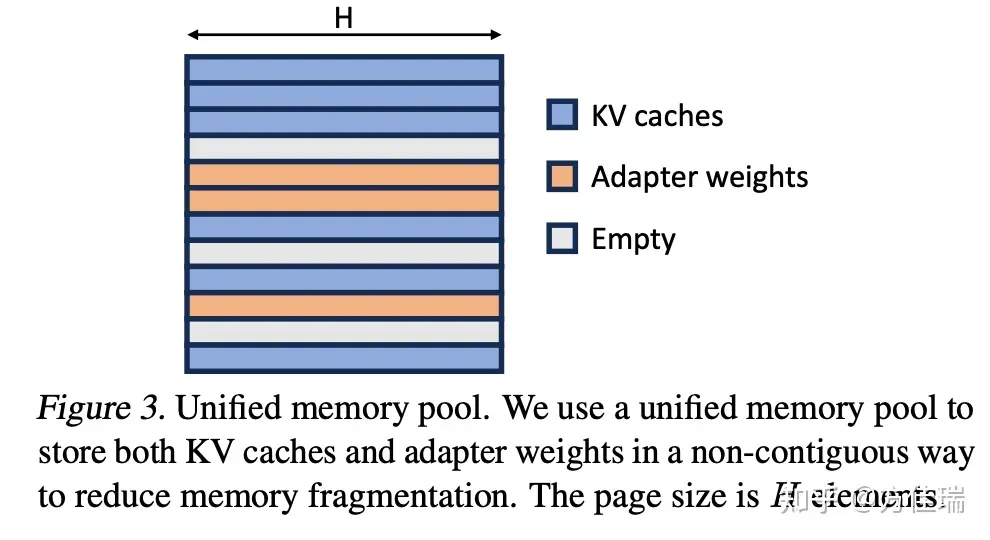
Unified Paging使用统一的内存池来共同管理 KV Cache 和 adapter weight。为了实现这一点,我们首先静态地为内存池分配一个大缓冲区。该缓冲区使用除 base model 权重和临时 activation 张量占用的空间之外的所有可用空间。图 3 展示了内存池的布局,其中 KV 缓存和适配器权重交错存储且不连续。这种方法显著减少了碎片化,确保各种秩 rank 的 adapter 权重能够以结构化和系统化的方式与动态的 KV Cache 共存。