Sora学习笔记
Published:
Diffusion Model
1. 正向过程定义
正向过程 (q) 将数据逐步添加噪声,直到变成一个简单的分布(通常是高斯分布):
\[q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\beta_t} x_{t-1}, \beta_t I)\]在第 (t) 步,数据 (x_t) 可以通过以下递推公式得到:
\[q(x_{1:T}|x_0) = \prod_{t=1}^{T} q(x_t|x_{t-1})\]2. 逆向过程定义
逆向过程 (p_\theta) 是通过去噪网络将噪声数据逐步还原为原始数据:
\[p_{\theta}(x_{t-1}|x_t) = \mathcal{N}(x_{t-1}; \mu_{\theta}(x_t, t), \Sigma_{\theta}(x_t, t))\]整个逆向过程可以表示为:
\[p_{\theta}(x_{0:T}) = p(x_T) \prod_{t=1}^{T} p_{\theta}(x_{t-1}|x_t)\]其中 (p(x_T)) 是初始噪声的分布。
3. 变分下界(Variational Lower Bound, VLB)
为了训练模型,我们需要最大化数据的对数似然:
\[\log p_{\theta}(x_0)\]直接优化这个目标非常困难,因此我们引入变分下界 (\mathcal{L}_{\text{VLB}}) 作为替代:
\[\log p_{\theta}(x_0) \geq \mathbb{E}_q \left[ \log \frac{p_{\theta}(x_{0:T})}{q(x_{1:T}|x_0)} \right] = \mathcal{L}_{\text{VLB}}\]
4. 变分下界展开
将变分下界展开,可以得到:

| 因为 (q(x_t | x_{t-1})) 和 (p_{\theta}(x_{t-1} | x_t)) 都是高斯分布,容易计算它们之间的 Kullback-Leibler 散度: |
5. 简化的损失函数(DDPM)
为了简化训练过程,通常使用一个容易计算的替代损失函数。具体方法是通过正向过程一步生成 (x_t):
\[x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t}\epsilon\]其中 (\alpha_t = 1 - \beta_t),(\bar{\alpha}t = \prod{s=1}^{t} \alpha_s)。这样可以直接从 (x_0) 生成 (x_t) 而无需逐步生成。最终损失函数可以表示为:
\[L_{\text{simple}} = \mathbb{E}_{t, x_0, \epsilon} \left[ \| \epsilon - \epsilon_{\theta}(x_t, t) \|^2 \right]\]6. DDIM(Denoising Diffusion Implicit Models)
正向过程与 DDPM 类似,DDIM 的正向过程也通过逐步添加噪声将数据变成高斯噪声:
\[q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I)\]逆向过程
DDIM 的逆向过程不同于 DDPM 的马尔可夫链方法,而是通过确定性方法进行采样:
\[x_{t-1} = \sqrt{\alpha_{t-1}} \left( \frac{x_t - \sqrt{1 - \alpha_t} \epsilon_{\theta}(x_t, t)}{\sqrt{\alpha_t}} \right) + \sqrt{1 - \alpha_{t-1}} \epsilon_{\theta}(x_t, t)\]这里,(\alpha_t) 是噪声调度参数,(\epsilon_{\theta}) 是预测噪声的去噪网络。
训练目标
DDIM 的训练目标与 DDPM 类似,都是通过最小化去噪误差来训练模型:
\[L_{\text{simple}} = \mathbb{E}_{t, x_0, \epsilon} \left[ \| \epsilon - \epsilon_{\theta}(x_t, t) \|^2 \right]\]SORA
数据预处理
在 SORA 里一个很重要的点就是,SORA 可以处理任何尺寸的图片和视频。
- 空间 patch 压缩:涉及将视频帧转换为固定大小的 patch,类似于 ViT(Vision Transformer) 和 MAE (Masked AutoEncoder)中使用的方法,然后将其编码到潜在空间中,这种方法对于适应不同分辨率和宽高比的视频特别有效。随后,将这些空间 token 按时间序列组织在一起,以创建时间 - 空间潜在表征。

- 时间 - 空间 patch 压缩:该技术旨在封装视频数据的空间和时间维度,从而提供全面的表示。该技术不仅仅分析静态帧,还考虑帧间的运动和变化,从而捕获视频的动态信息。3D 卷积的利用成为实现这种集成的一种简单而有效的方法。
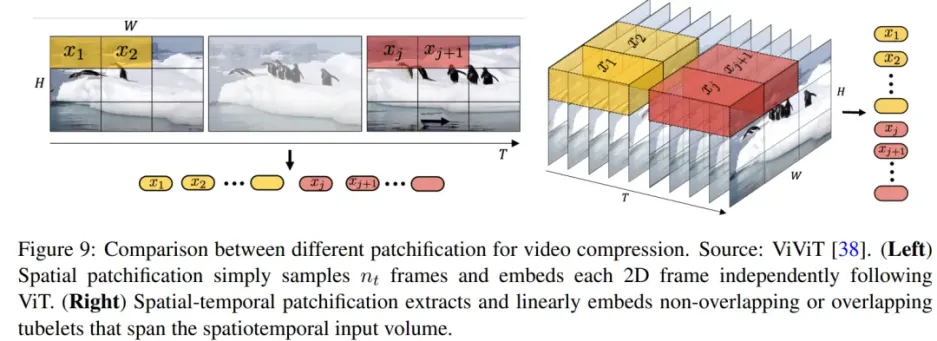
视频的采样有两种:
- 将输入视频划分为 token 的直接方法是从输入视频剪辑中均匀采样帧,使用与 ViT 相同的方法独立地嵌入每个 2D 帧,并将所有这些 token 连接在一起。
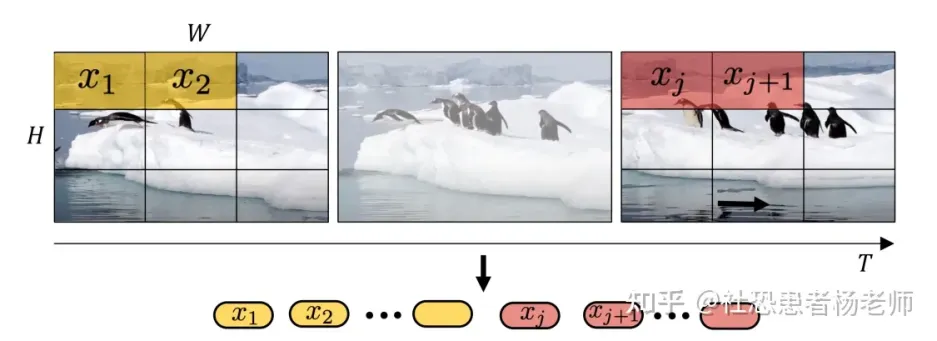
- 把输入的视频划分成若干个 tuplet(类似不重叠的带空间-时间维度的立方体),每个 tuplet 会变成一个 token(这个 tuplet 包含了时间、宽、高),经过 spatial-temporal attention 进行空间和时间建模获得有效的视频表征 token。
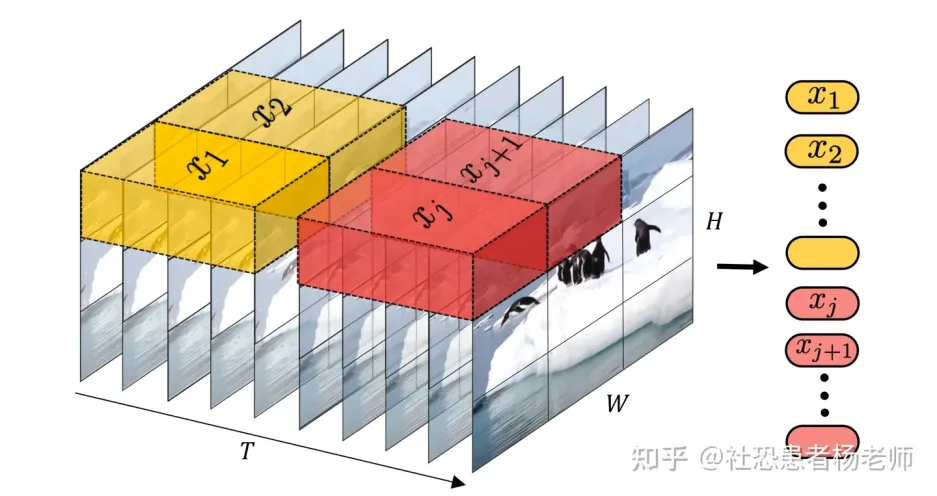
Sora 之所以强大,是因为不同于以往需要预处理且要求图片和视频大小一致的文本转视频方法,它基于“Patch”而非整个视频帧进行训练,能处理任意大小的视频或图片,无需裁剪,让 OpenAI 能够在大量数据上训练 Sora,提高输出质量。
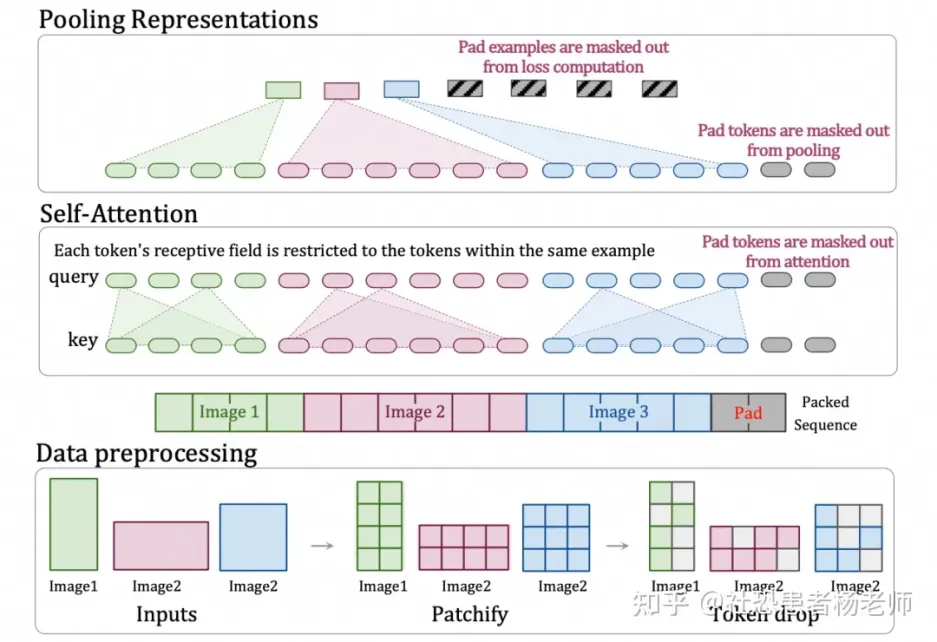
此外,Sora 采用了 Google 的 Patch n’ Pack 技术,将多个 patch 打包成一个序列,支持动态分辨率视频输入,减少了计算负载不均衡,同时根据图像相似度丢弃雷同的图像块,降低了训练视频的成本。
建模
SORA 的模型可能是基于 Diffusion-Transformer(DiT)架构,出自《Scalable Diffusion Models with Transformers》。OpenAI 是第一个使用这种架构在大规模数据上进行训练的。简单来说,Diffusion-Transformer(DiT)是一个带有 Transformer Backbone 的扩散模型: \(\text{DiT} = [VAE \text{编码器} + ViT + DDPM + VAE \text{解码器}]\)
但把 DPPM 中的卷积 U-Net 架构换成了 Transformer。
图像Dit
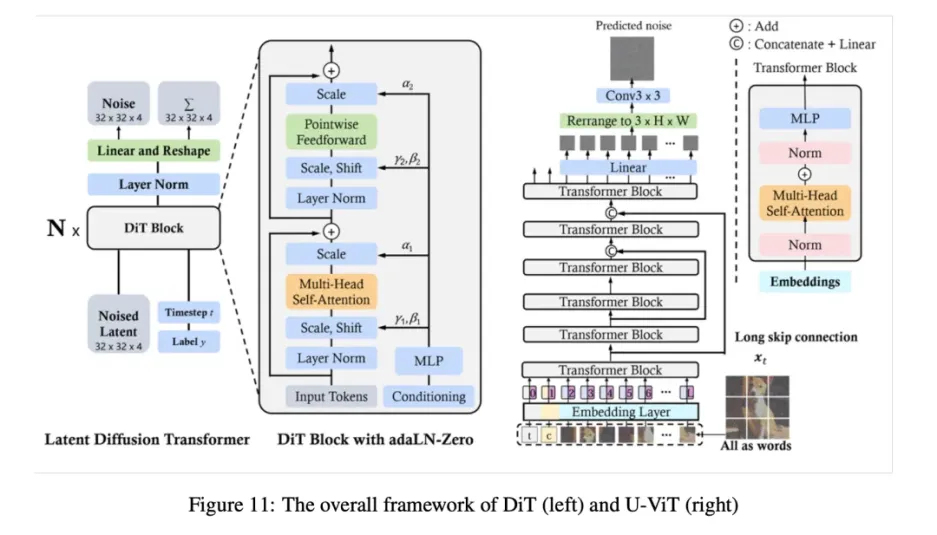
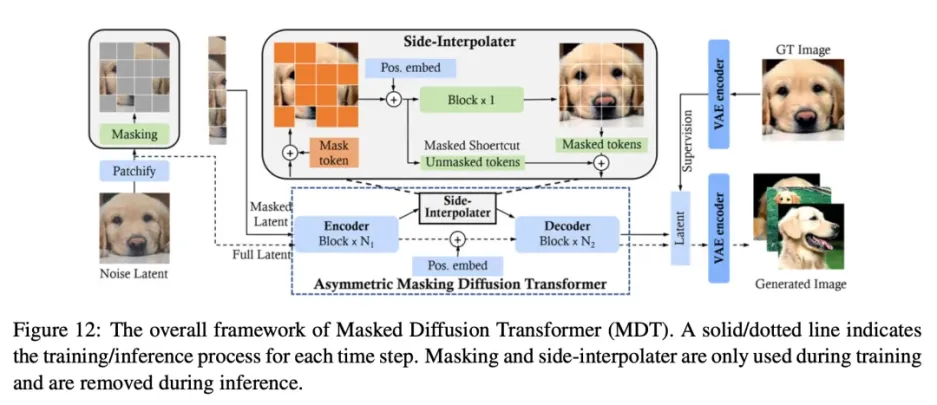
视频Dit
在文本到图像(T2I)扩散模型的基础上,一些近期研究专注于发挥扩散 Transformer 在文本到视频(T2V)生成任务中的潜力。由于视频的时空特性,在视频领域应用 DiT 所面临的主要挑战是:
- 如何将视频从空间和时间上压缩到潜在空间,以实现高效去噪。
- 如何将压缩潜在空间转换为 patch,并将其输入 Transformer。
- 如何处理长序列时空依赖性,并确保内容一致性。
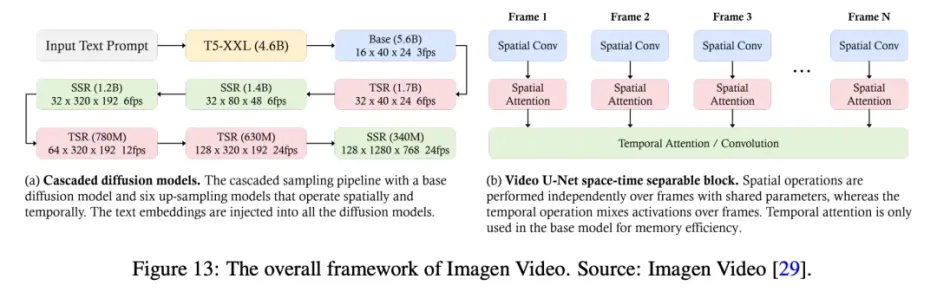
Imagen Video 是谷歌研究院开发的文本到视频生成系统,它利用级联扩散模型(由 7 个子模型组成,分别执行文本条件视频生成、空间超分辨率和时间超分辨率)将文本提示转化为高清视频。
首先,冻结的 T5 文本编码器会根据输入的文本提示生成上下文嵌入。这些嵌入对于将生成的视频与文本提示对齐至关重要,除了基础模型外,它们还被注入级联中的所有模型。随后,嵌入信息被注入基础模型,用于生成低分辨率视频,然后由级联扩散模型对其进行细化以提高分辨率。基础视频和超分辨率模型采用时空可分离的 3D U-Net 架构。该架构将时间注意力层和卷积层与空间对应层结合在一起,以有效捕捉帧间依赖关系。它采用 v 预测参数化来实现数值稳定性和条件增强,以促进跨模型的并行训练。
这一过程包括对图像和视频进行联合训练,将每幅图像视为一帧,以利用更大的数据集,并使用无分类器引导来提高提示保真度。渐进式蒸馏法用于简化采样过程,在保持感知质量的同时大大减少了计算负荷。将这些方法和技术相结合,Imagen Video 不仅能生成高保真视频,而且还具有出色的可控性,这体现在它能生成多样化的视频、文本动画和各种艺术风格的内容。
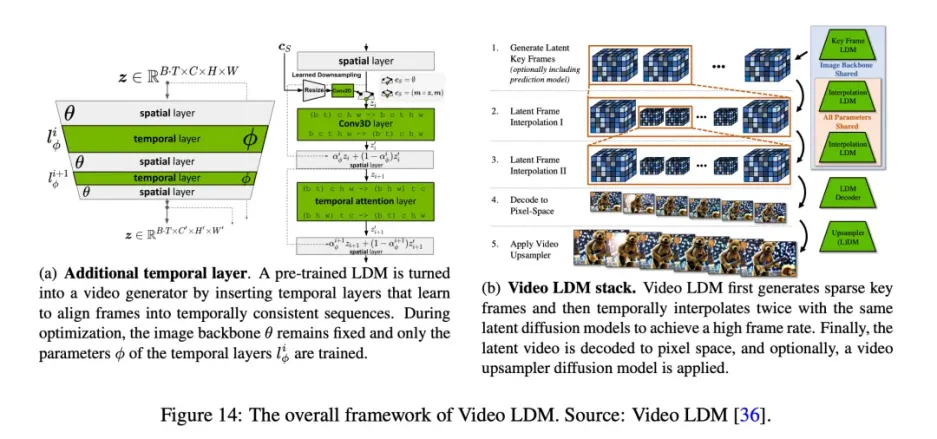
Blattmann et al. 建议将二维潜在扩散模型转化为视频潜在扩散模型(Video LDM)。为此,他们在 U-Net 主干网和 VAE 解码器的现有空间层中添加了一些临时时间层,以学习如何对齐单个帧。这些时间层在编码视频数据上进行训练,而空间层则保持固定,从而使模型能够利用大型图像数据集进行预训练。LDM 的解码器可进行微调,以实现像素空间的时间一致性和时间对齐扩散模型上采样器,从而提高空间分辨率。
为了生成超长视频,作者对模型进行了训练,以预测未来帧的上下文帧数,从而在采样过程中实现无分类器引导。为实现高时间分辨率,作者将视频合成过程分为关键帧生成和这些关键帧之间的插值。在级联 LDM 之后,使用 DM 将视频 LDM 输出进一步放大 4 倍,确保高空间分辨率的同时保持时间一致性。这种方法能以高效的计算方式生成全局一致的长视频。此外,作者还展示了将预先训练好的图像 LDM(如稳定扩散)转化为文本到视频模型的能力,只需训练时间对齐层,即可实现分辨率高达 1280 × 2048 的视频合成。