Efficient Scaling Transformer Inference 论文精读
Published:
Challenge
Transformer-based model 的训练和推理两个部分的时间消耗差异很大。由于推理过程生成 Token 的过程的输入需要上一次生成的输出,导致对推理过程并行化减少时间消耗是很困难的。同时,随着推理得到的信息越来越多,需要的空间开销和对内存的读写也会以平方级增长。
两个优化思路
一些优秀的分割策略
对 feedforward 层和 attention 层均研究了张量并行的一些不同的分割策略,并根据实际阶段、参数量来选择更好的分割策略,达到最优效果。
进行了 Memory optimization
利用 multi-query attention 来减少 KV-cache 大小,并根据 prefill,generation 来选择更好的并行策略,从而减少内存大小和内存读写量。
Partition Strategy on Feedforward Layer
基础概念和优化目标
Feedforward Layer 会读入 $B$ (batch size) 个大小为 $L$ ( Embedding 个数)个长为 $E$ ( Embedding 长度)的向量,并对这些矩阵与大小为 $E \times F$ 的权重矩阵做乘法,进入激活函数,最后再与 $F \times E$ 的权重矩阵做乘法,得到输出。
现在我们想要实现张量并行,也就是通过合理的分块方法对 $E \times F$ 的权重矩阵进行分块再进行矩阵乘法再进行合并。
本文使用 TPU v4 芯片,其有 3D 结构 $X\times Y\times Z$ 。
AllGather,ReduceScatter,All-to-All 三个基本概念
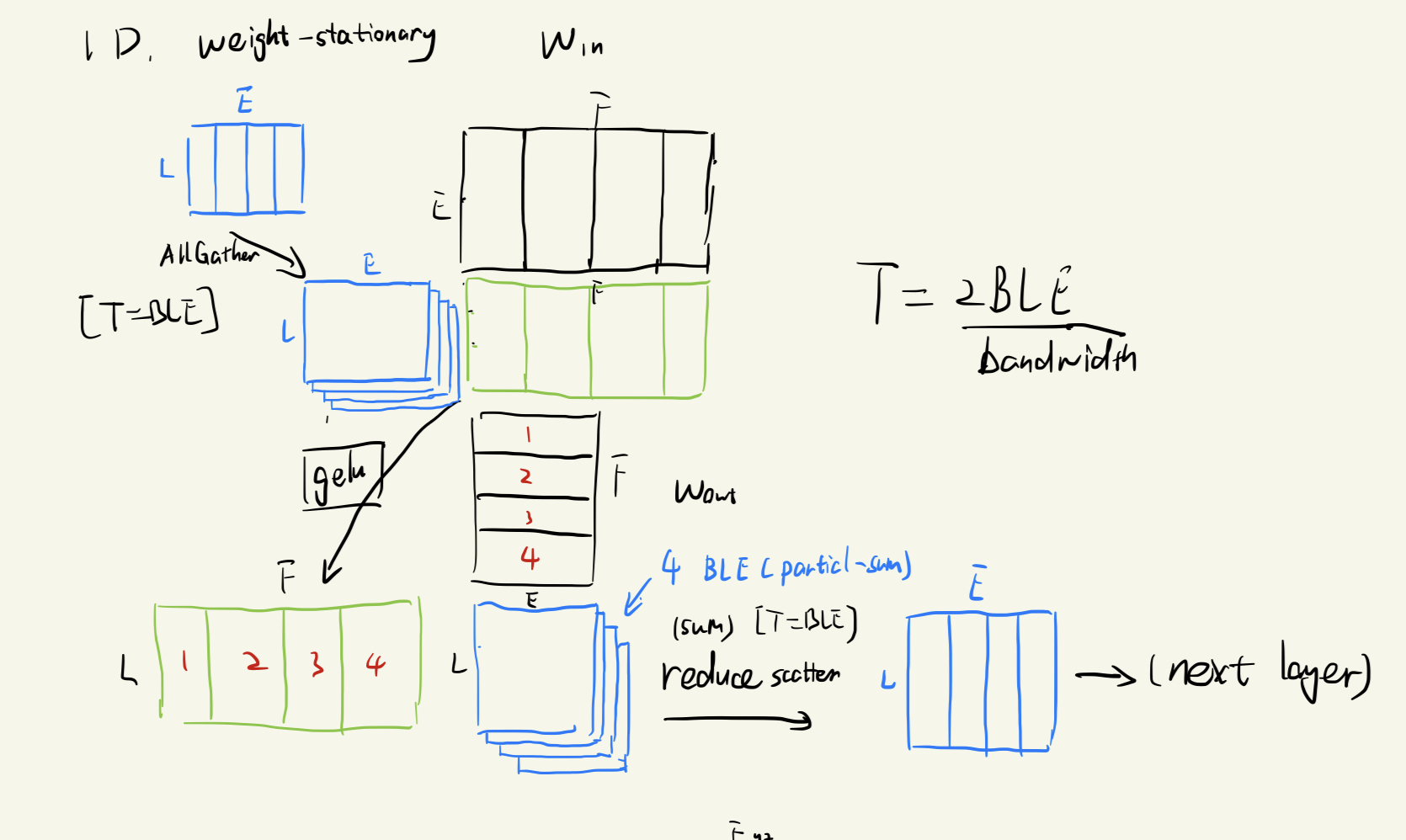
1D weight-stationary layout
对每个权重矩阵按照 $E$ 或 $F$ 的一维分割成 $xyz$ 块并存入每个芯片上,并且与对应的激活矩阵部分相乘。
1D 分割方法是只分割激活矩阵的 $E$ 这一个维度,具体计算流程见图。
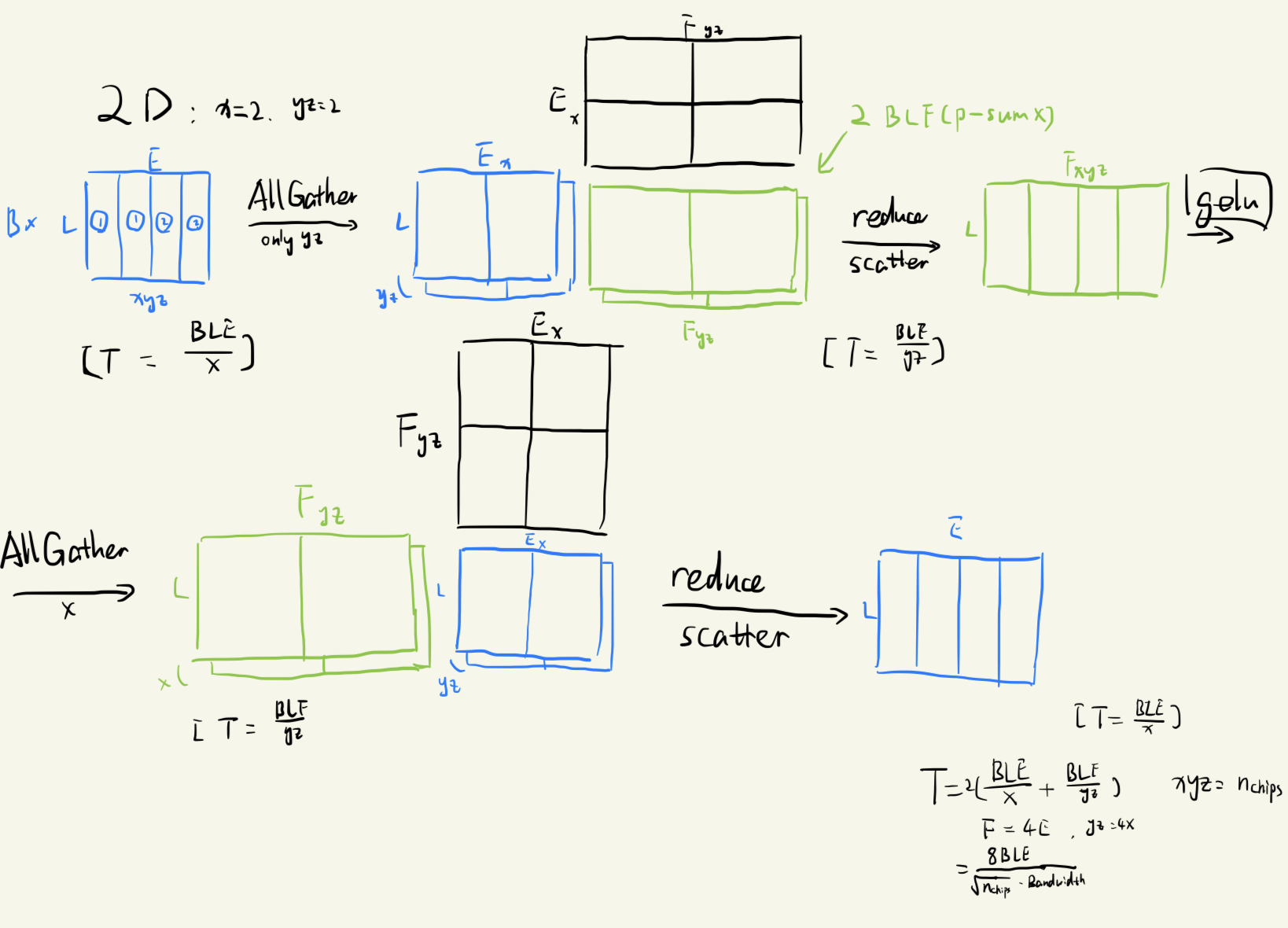
2D weight-stationary layout
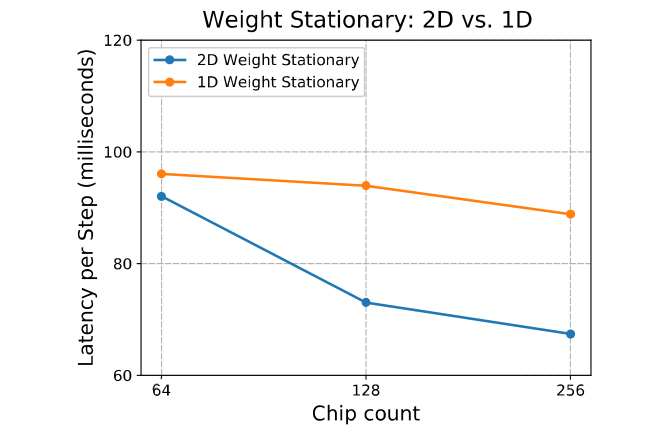
2D 分割方法同时分割了 $E$ 和 $F$ 两维。最后得到的结论是 2D 分割方法得到的结果在 chip 数量增加时通讯时间会不断减少,在 $n_{chips}$ 大于 $16$ 时候比 1D 方法更好。具体流程同样见图。
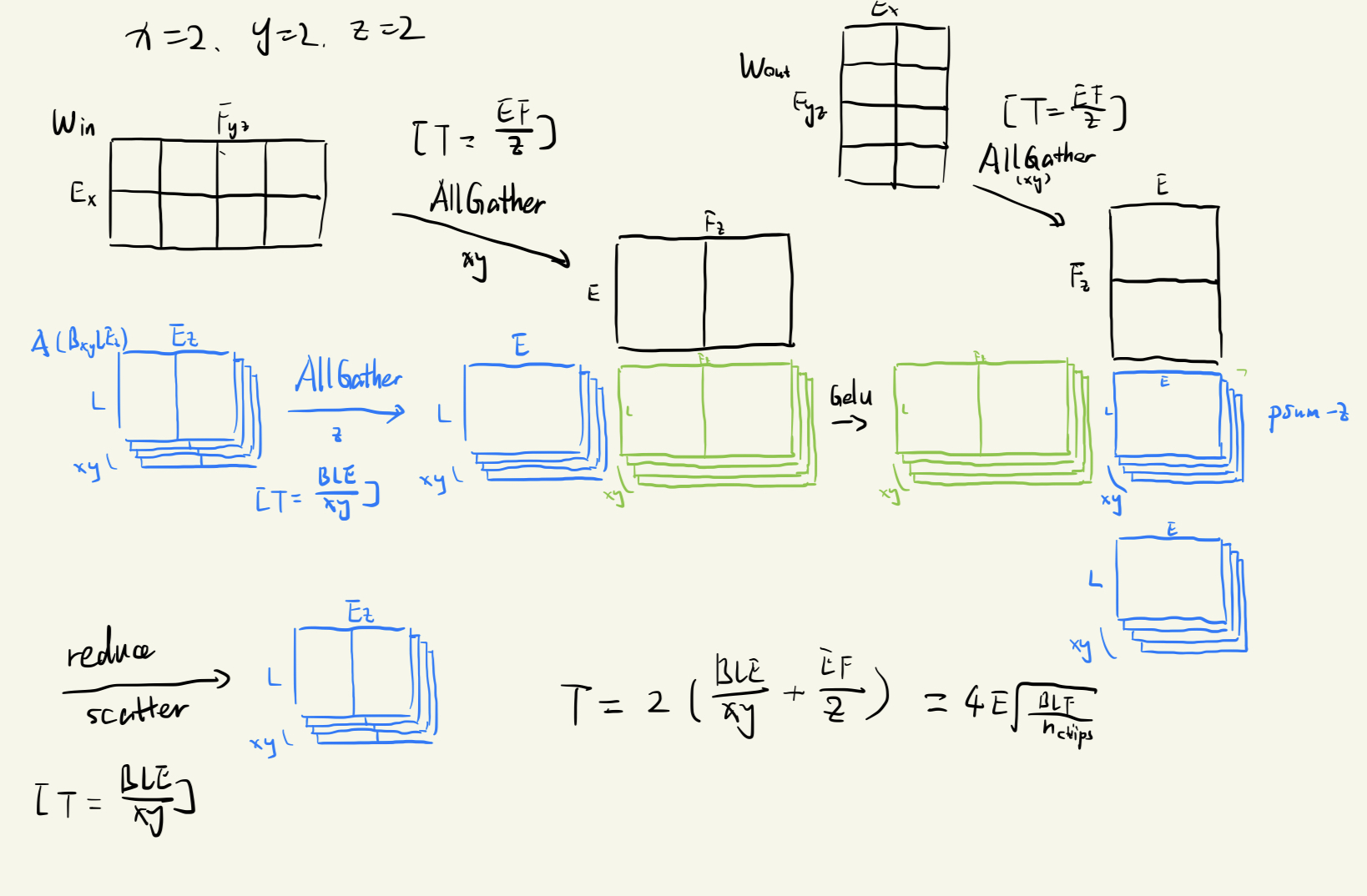
Weight-gathered
在前两种方法中,随着 batch size 提高,芯片之间传输的激活矩阵大小提高非常快,但是权重矩阵几乎没有改变。因此可以想到如果把激活矩阵放到核中并且让权重矩阵在核之间传输更加经济。保证全部 weight-gathered 是 XYZ-weight-gathered ,同时存在只有一部分权重矩阵和一部分激活矩阵进行交换的方法,是 X-weight-gathered 和 XY-weight-gathered 。
下面图示为 XY-weight-gathered 的方法:
在 Batch Size 较小的时候,2D-weight-stationary 表现非常好,随着 batch size 变大,逐渐使用不同的 weight-gathered 。
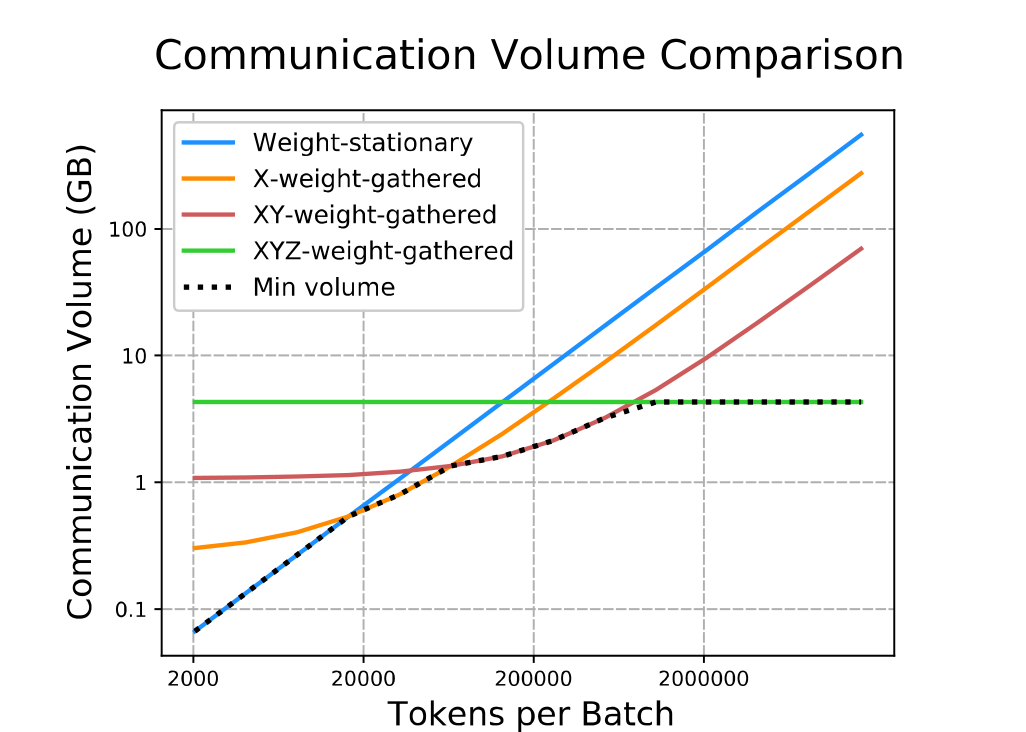
以上策略的效果可以看结果部分。
Partitioning the Attention Layer
优化方向
Multi-head Attention 阶段只需要把 $d_{ff}$ 改成 $n_{heads}$ 就可以用和上面 Feedforward 层相同的并行策略。但是 Multi-head Attention 在推理过程中对 KV-cache 的读和写的过程以及内存的消耗是非常高的,并且在整个模型的效率中占主要影响。因此为了应对长文本的推理,我们需要考虑怎么优化这个部分,也就是优化不断读写 KV-cache 带来的消耗。
Multi-query Attention
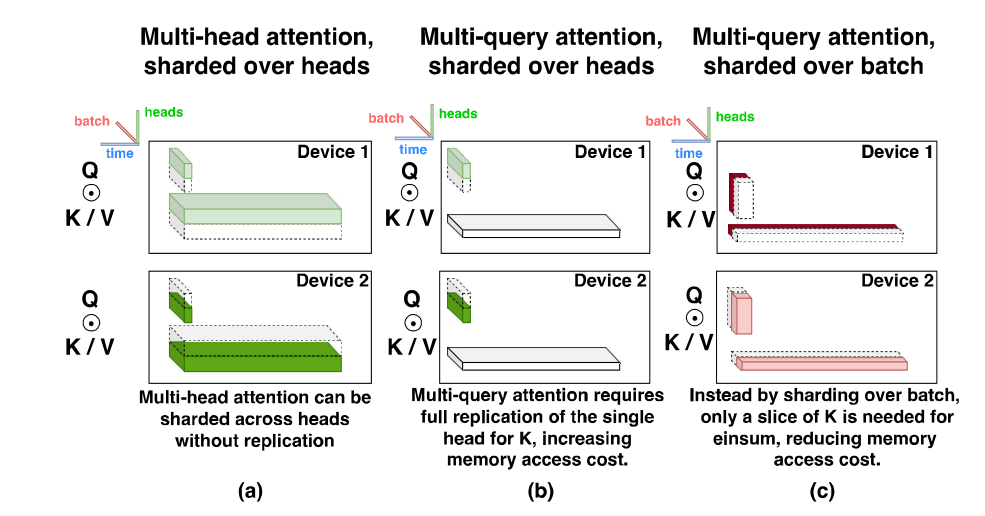
在推断过程中,多头注意力机制中每个头都对应了一个 KV-cache ,这里需要非常高得内存消耗。所以这里用到了其他论文中的 Multi-query Attention 机制,使得每个头中只保存 query ,但共用同一对 KV ,于是对空间消耗带来了很大的降低。
为了使用 Multi-query Attention 来降低内存消耗,就需要按照 batch size 来并行,不能按 $n_{head}$ 来。因为如果按 $n_{head}$ 来并行,每个 device 同样需要存储整个 KV 矩阵。但是如果按照 batch size 来,每个 device 中只需要存储一部分的 KV 矩阵,达到减少内存消耗的目的。而且这样随着用的芯片更多,内存消耗只会越少。
但是由于最终计算 multi-query attention 输出的时候是需要对每个 $n_{heads}$ 得到输出并且进入线性层,因此按 batch size 并行的劣势在于需要在通过每个 head 的 linear 层时得到的矩阵先把按 $n_{heads}$ 分开的东西变成按 batch size 分开的东西,并且在计算结束后将按 batch size 计算的东西变回按 $n_{heads}$ 分开的东西。这需要两次 all-to-all 操作。
Prefill & Generation
Prefill 阶段是一次获得 prompt 中的所有 token 作为 query ,但是它只需要进行一次计算,这个过程是并行的,从而获得 KV-cache 。在这个阶段中 query 中一次进入很多 token 并对同一个 KV-cache 进行操作,因此加载 KV-cache 的时间就被摊还到了所有 query 上,所以 Memory load 部分并不是 prefill 的瓶颈,因此在这个阶段我们直接使用和前面一样的按 $n_{heads}$ 并行的方法。
Autoregressive generation 阶段有一定差异。这个阶段每次进入一个 token 得到的 Q,K,V 矩阵,但是 KV-cache 同样是很大的矩阵,因此我们要尝试按 batch size 执行并行。并且这个时候对一个 token 得到的 Q,K,V 矩阵执行 all-to-all 操作的代价是不高的。
其他优化
Parallel attention and feedforward layer
还使用了一种比较简单的并行手段。作者直接将一个 encoder 层中的 attention 机制和 feed-forward 层同样用正则化的输入来计算并且相加得到当前层的输出。
Low-level Optimization & Quantization
最后作者介绍了一些自己使用的底层优化,例如对 einsum 的优化。并使用 AQT 减少了内存消耗。
Case study for PaLM Models
Feedforward Partition Strategies 的选择
随着 chip 数量增加,feedforward 层的延迟:
随着 batch size 增加,stationary gathered 和 weight gathered 的效率:
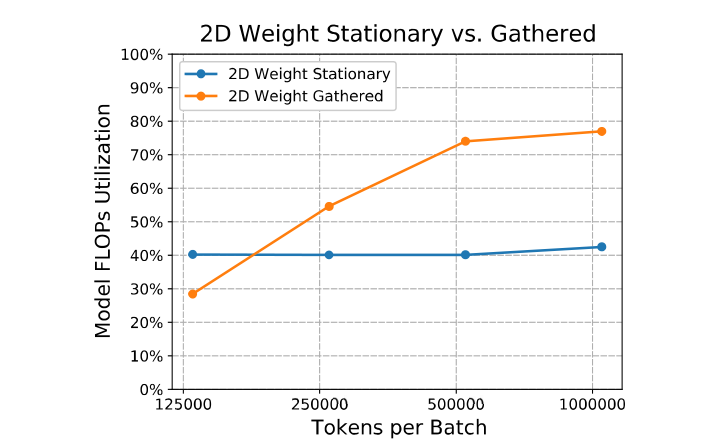
可以看出 batch size 较小时使用 weight stationary 策略更优,否则使用 weight-gathered 策略更优。
因此:
- 在 prefill 阶段,我们通过 batch size 的大小在 weight-gathered 和 weight-stationary 策略中进行选择。
- 在生成阶段,我们选择 2D-weight-stationary 因为 batch size 总是非常小。
Attention Layer Partitioning
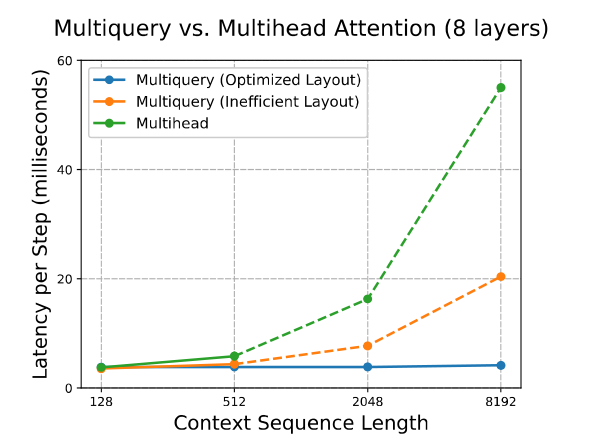
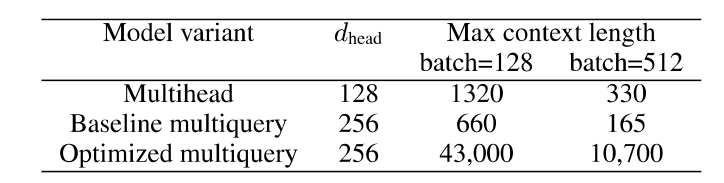
随着 context length 增加,KV-cache 会不断增加,从而导致内存不足。相对于一般的 multi-head attention 和一般的 multi-query attention ,优化后的模型的 Max context length 大约在 32-64 倍之间。
在 prefill 阶段,优化的 multiquery 在延迟上与一般的 multihead 差异不大。但是在生成阶段,随着生成的 context length 不断增加,读取 KV-cache 导致的延迟越来越高,优化后的效果越来越明显。