Efficient Memory Management for Large Language Model Serving with PagedAttention 论文精读
Published:
Introduction
在大部分基于 transformer 的 LLM 中,其内存占用相当庞大,而其中模型参数和 KV 缓存是最为主要的内存消耗。目前大部分工作集中于模型参数在内存占用的优化但忽视了 KV 缓存所带来的内存占用,而作者团队的工作集中于 KV 缓存的管理上,并且取得了较好的效果。
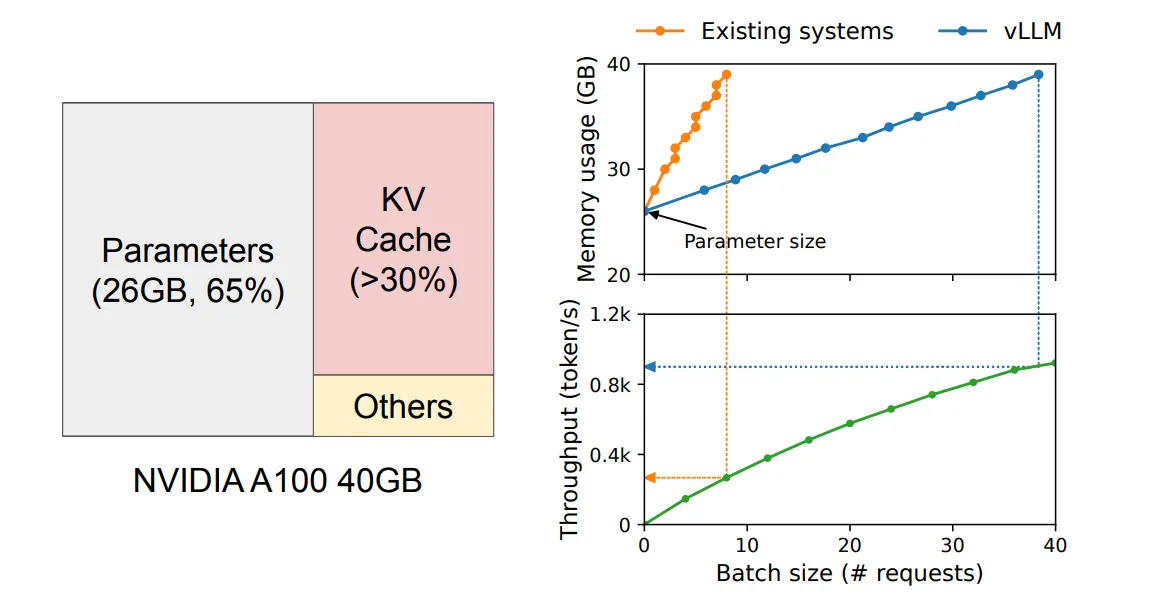
下面左图是在 NVIDIA A100 上为 13B 参数的 LLM 提供服务时的内存布局,右图表明 vLLM 平滑了现有系统中 KV 缓存内存的快速增长曲线,显著提高了服务吞吐量。
作者团队发现在常见的 KV 缓存方法中,存在明显的内存浪费现象,这个发现启发了作者设计一种更高效的处理 KV 缓存的系统。在常见的 KV 缓存方法中,存在以下三种主要的内存浪费:
- 为未来将产生的 token 预留的空间。(reserved)
- 为可能的最长序列长度进行超额分配产生的内部内存碎片。(internal fragmentation)
- 不同请求之间间隔的外部内存碎片。(external fragmentation)
(1 和 2 都是提前预留给一个请求的空间,区别在于,当请求完成时,被占用了的称为预留,而未被使用的称为内部碎片。之所以认为预留空间也是浪费,是因为在同时进行若干请求时,还未被使用的预留空间可能能被其他请求先使用掉。)

Challenge
作者团队基于 KV 缓存优化所设计的 vLLM 主要面临以下三种挑战:
- 庞大的 KV 缓存量(主要挑战,也是论文的核心出发点)
- 复杂的解码算法(包括一个 request 采样若干 output 以及进行 beam search,或者使用不同的编码方式,和应对相同前缀的 request)
- 关于不同 requests 的调度和占用问题。
Background
transformer 相关知识。
Method
该系统的核心部分:PagedAttention 和 KV Cache Manager。
PagedAttention
我们将 KV 缓存分成若干块,每块存储 B 个 k 和 v,例如:
\(K_j = (k_{(j-1)B+1},...,k_{jB})\)
\(V_j = (v_{(j-1)B+1},...,v_{jB})\)
而我们定义新的 self-attention 计算方式为:
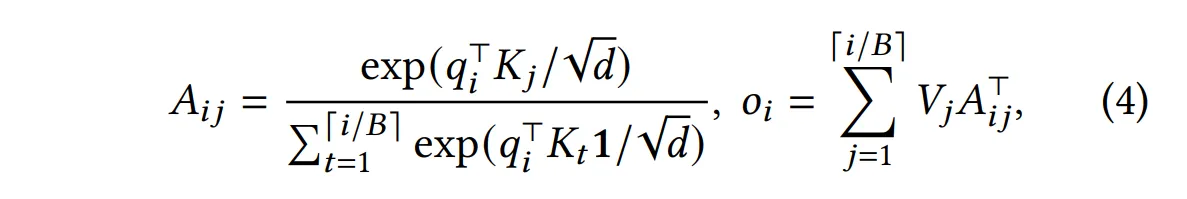
(即先每块内部进行 self-attention 计算然后再加到一起,再用 exp 的总和计算 softmax 分发给每个块的 V)
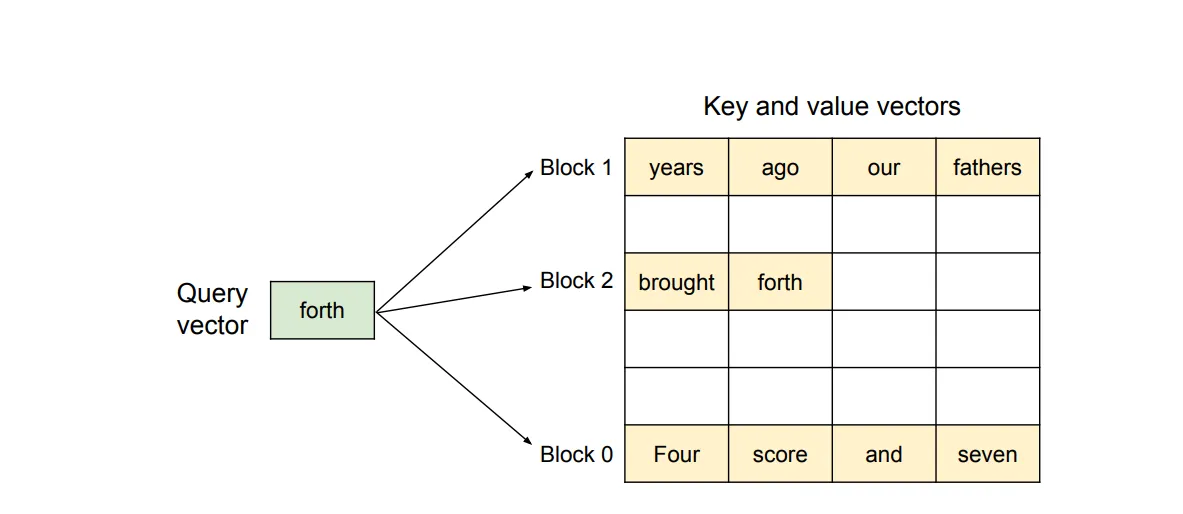
KV Cache Manager
这个部分设计了分块后的 KV 缓存的管理方式(实际上就是块状链表)。思路非常简单:将整个 KV 缓存按块分割并编号,在分配空间时,只需要分配块的编号即可,不需要实际在物理上连续分配内存。对于多 request 也是只需要分配块的编号。
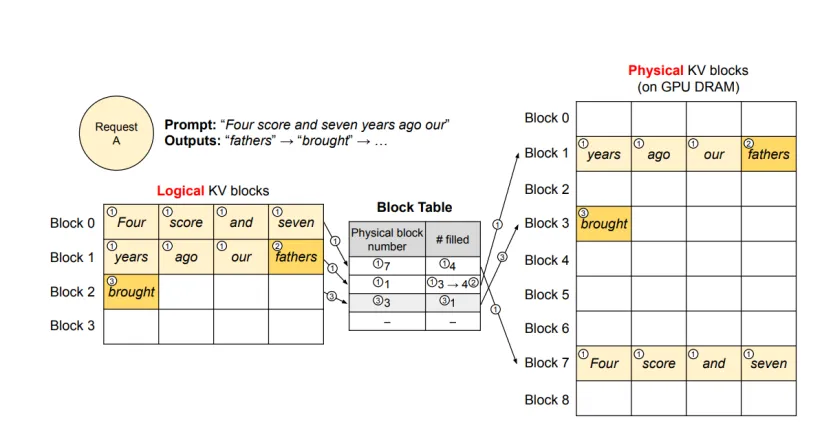
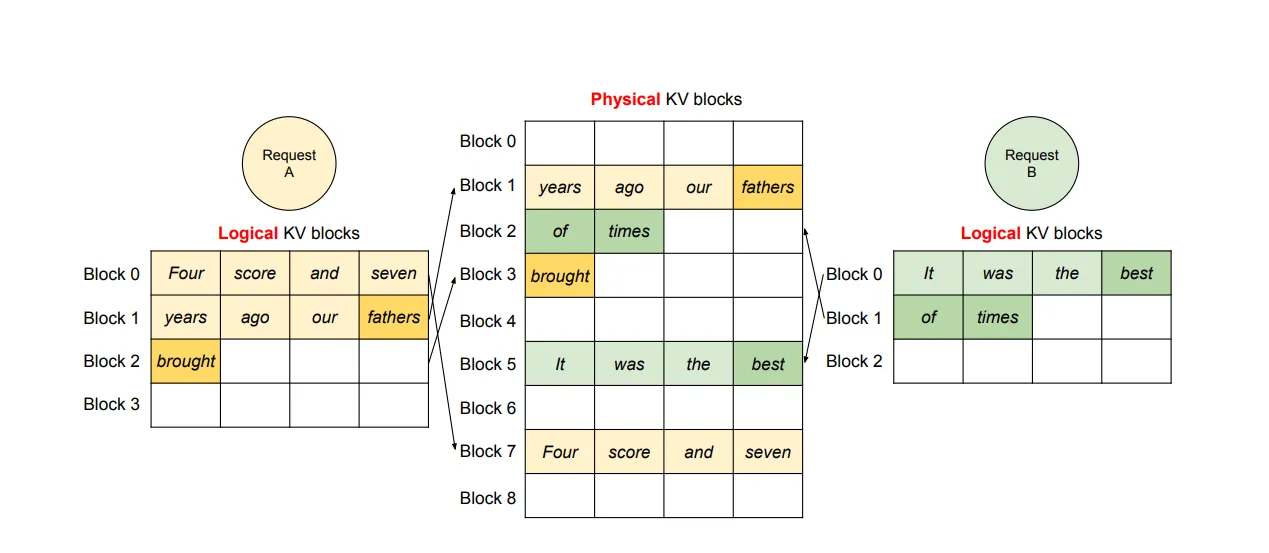
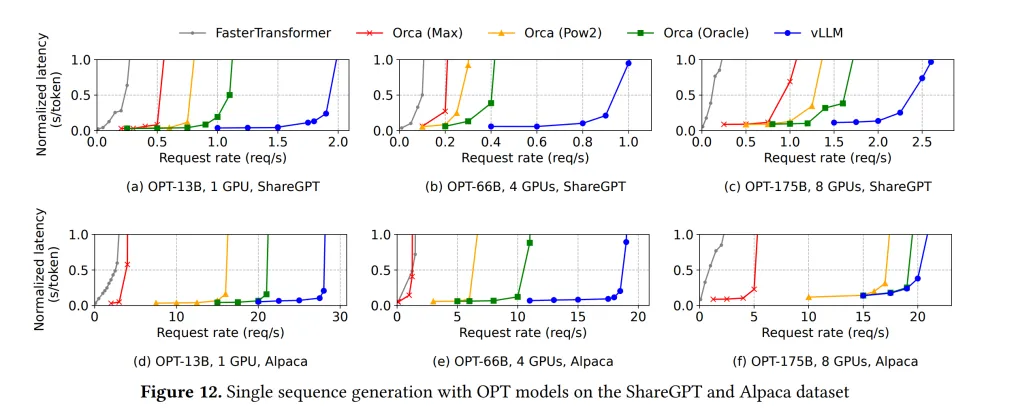
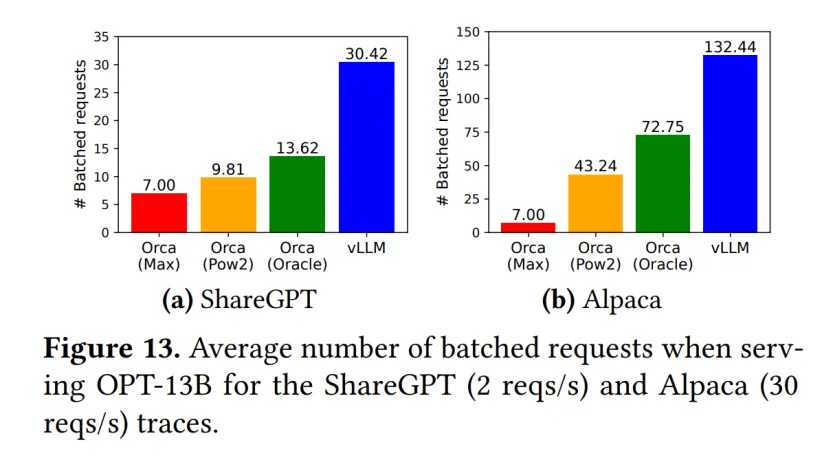
在块大小的选取上有不少讲究,块过小会使访问效率变低,但块过大又会导致空间浪费过大。论文在 ShareGPT 和 Alpaca 数据集上进行测试,认为块大小选 16 比较合适。
Application to Other Decoding Scenarios
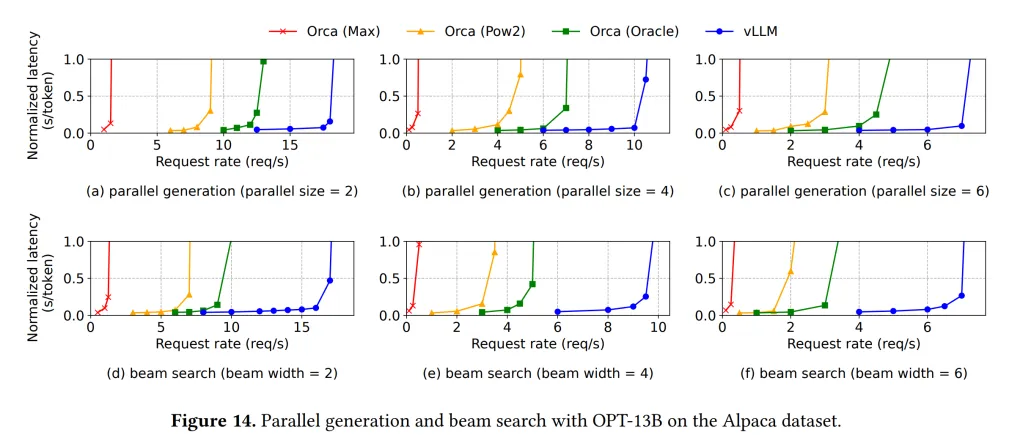
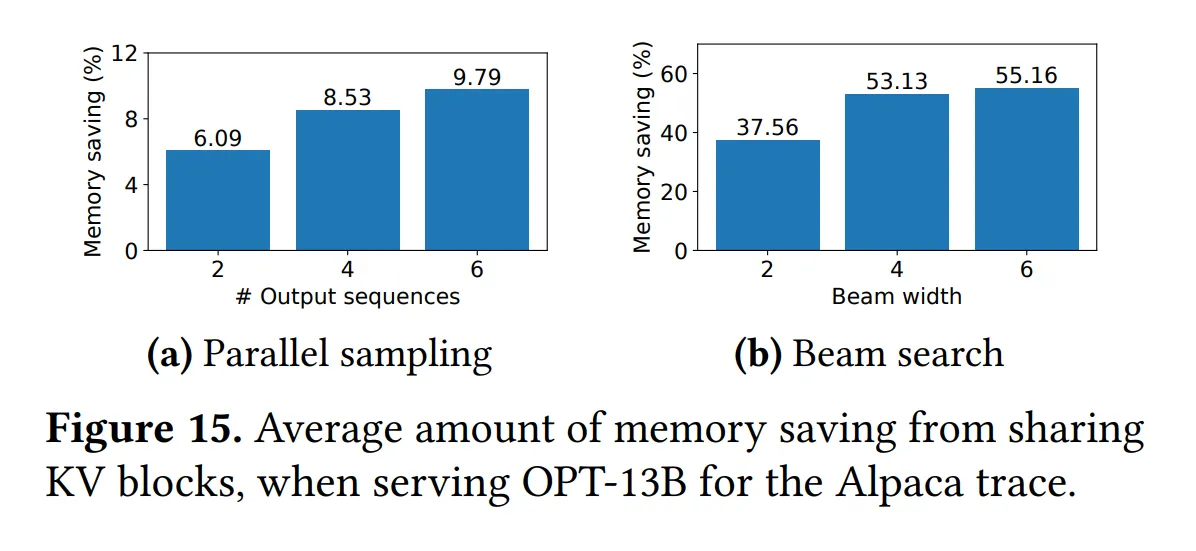
Parallel sampling
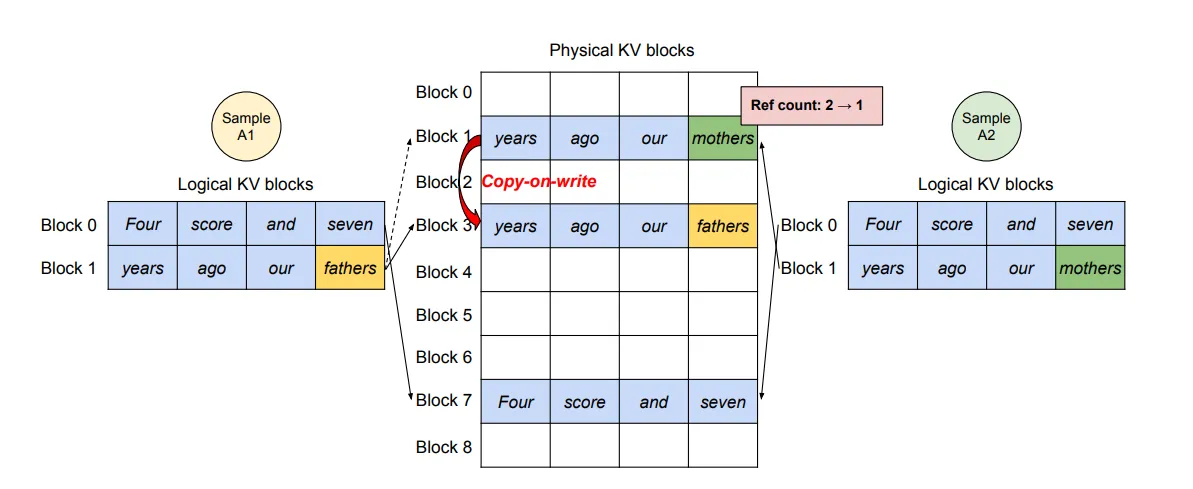
一些优秀的模型需要同时采样不同的结果,即对于相同的输入,并行采样得到不同的输出(因为相同的输出可能导致不同的结果)。但由于不同输入的输出结果具有相同的部分,因此可以共用同一个块。
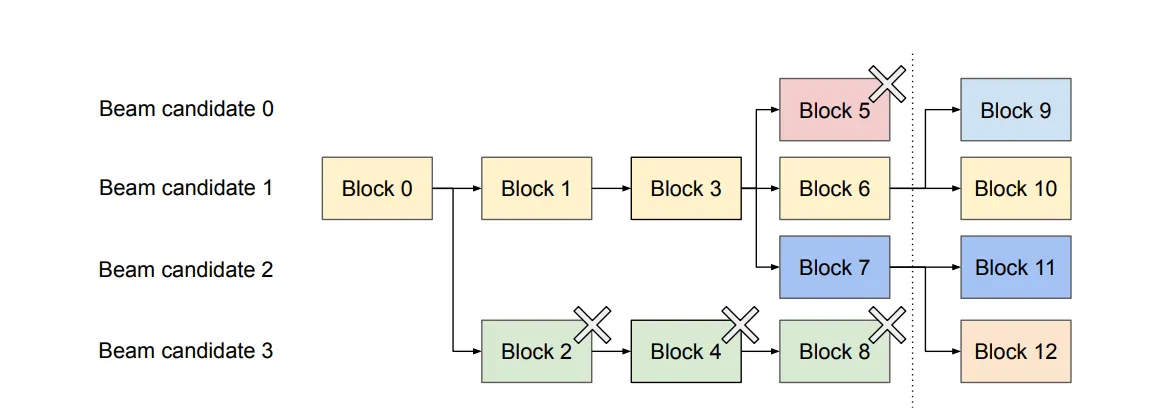
Beam search
部分模型也会用到 Beam search。Beam search 类似于 k 短路,要求出前 k 个最好的结果(关于“好”的定义,每个模型有自己的定义方法),而 Beam search 也类似于 Parallel sampling,会有不少块可以共用(类似于 k 短路的搜索树)。
Shared prefix
对于某一些应用,输入给 LLM 的提示词的前缀可能是某种模板提示词,例如,你希望进行翻译工作,就会用“将以下文本翻译为中文”的提示词模板,而这种相同的前缀,在作者设计的系统中依旧是可以共享的。
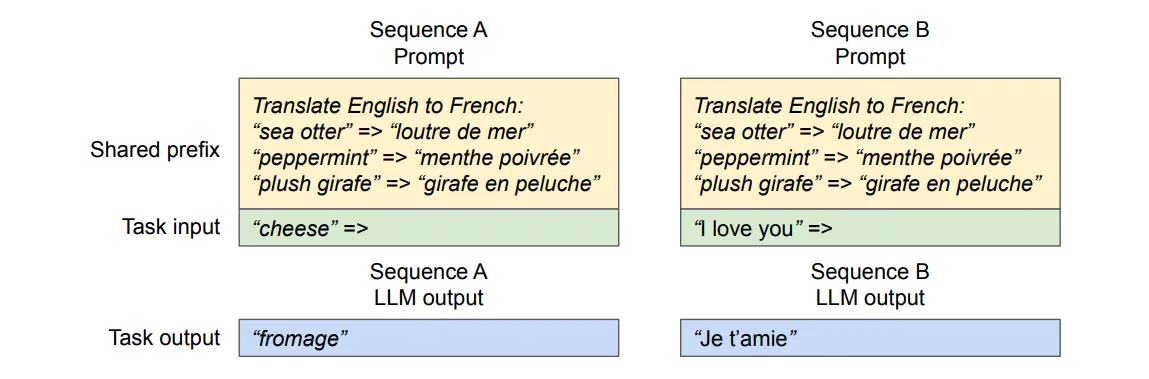
(在作者设计的系统中,Shared prefix 部分的 token 会被共享)
Mixed decoding methods
某些模型为了更优秀的效果,会使用不同的解码策略,vLLM 便于同时处理具有不同解码偏好的请求,这是因为 vLLM 通过一个通用的映射层将不同序列之间的复杂内存共享隐藏起来,将逻辑块转换为物理块。
(以上应用几乎同质,都是共享相同的前缀 token)
Scheduling and Preemption
由于实际的推理过程可能会将所有的显存占满,这时需要进行调度将某些 request 给关闭。本系统的调度原则为 first-come-first-serve。先加入的 request 优先计算,后加入的 request 优先关闭,具体的关闭手段如下:
Swapping
将准备关闭的 request 的 KV 缓存下载到 CPU。
Recomputation
将准备关闭的 request 的 KV 缓存删掉,但将已经生成的 token 添加到原 request 的末尾,在之后重新拉起该 request 时重新计算。
(本系统会计算 Swapping 和 Recomputation 的效率,选择最优的决策。)
Distributed Execution
vLLM 可以与其他模型并行策略一起使用。
Evaluation